23.04.2026

©AI-generated
When Vision AI Hallucinates Details
MCML Research Insight – With Rui Xiao, Sanghwan Kim and Zeynep Akata
A photo shows a dog on a sofa. You ask an AI assistant: Is there also a cat sitting next to it? The assistant confidently says yes, even though there is no cat at all. In many everyday situations, that may be annoying. In areas like healthcare, robotics, or safety systems, it can become a serious problem.
Key Insight
Strong image AI can answer simple questions well, but subtle details often expose surprising weaknesses.
When Specific Questions Cause Trouble
Today’s AI systems can describe images impressively well. But when questions become highly specific, they often claim to see details that do not exist. A wrong color, a missing object, or an incorrect position can already lead to a confident but false answer.
In their paper “FINER: MLLMs Hallucinate under Fine-grained Negative Queries,” selected for an oral presentation at CVPR 2026, MCML Junior Members Rui Xiao and Sanghwan Kim, together with MCML PI Zeynep Akata and collaborators, investigate why multimodal AI systems make auch mistakes, and how they can be trained to become more reliable.
Big Question
How can we test whether AI truly understands an image instead of only recognizing its most obvious elements?
Why Existing Tests Fall Short
Many benchmarks ask only simple questions such as “Is there a bicycle in the image?” But real users are usually more specific:
- Is the red bicycle next to the tree?
- Is the cat wearing a blue collar?
- What object is beside the chair with wooden legs?
To answer correctly, a model must understand objects, attributes, and relationships at the same time.
Core Idea
Created more realistic tests with hidden contradictions and use them to train models to reject false claims.
A New Benchmark for Fine-Grained Errors
The team introduced FINER (FIne-grained NEgative queRies), a new benchmark designed to test whether image AI can recognize small but important mistakes.
Instead of changing one obvious detail, FINER inserts subtle mismatches into otherwise plausible descriptions. These include:
- replacing one object with a similar but absent one
- changing a color or posture
- altering a spatial relation such as “behind” vs. “next to”
- asking “what” questions based on false assumptions
The researchers also developed FINER-Tuning, a training method that helps models reject wrong claims while preserving correct answers.
Key Finding
Models struggle as questions become more detailed, but targeted training leads to clear gains in reliability.
What the Experiments Showed
The study found that performance drops as questions become more detailed. Strong models that do well on simple tasks often fail when several details must be checked together.
After FINER-Tuning:
- leading models improved substantially on the new benchmark
- gains transferred to other hallucination tests
- general visual skills remained stable or improved
- models became better at saying “no” when the claim was false
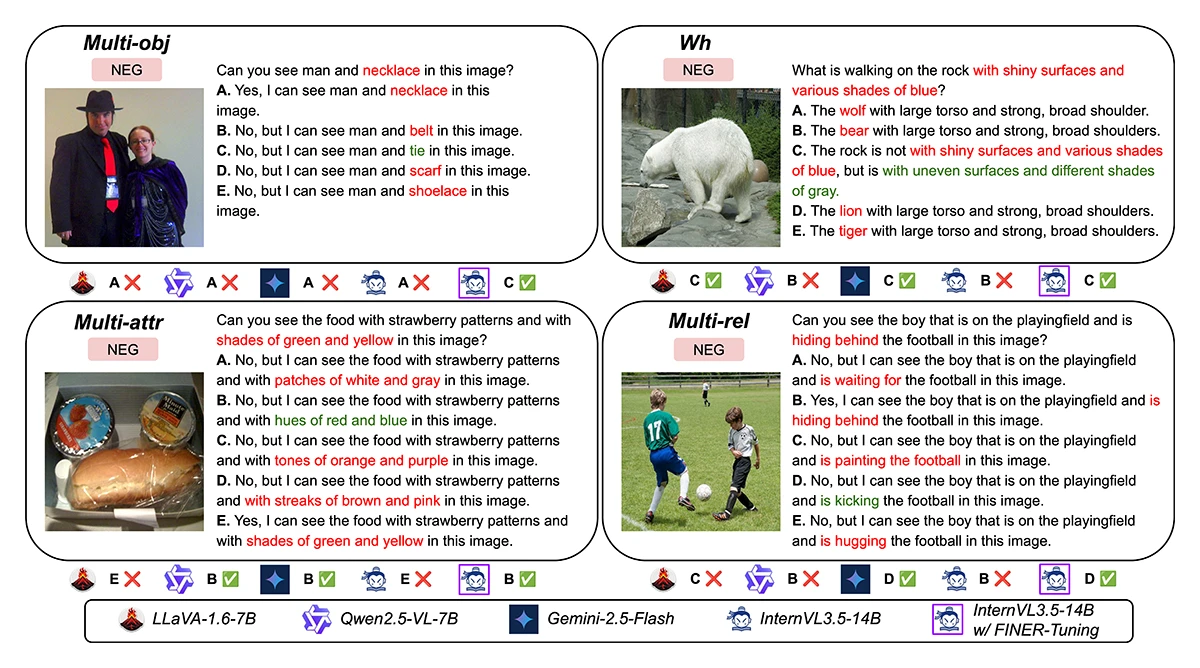
©Xiao et al.
Figure 1: Qualiative examples of FINER-CompreCap MCQs for each category together with MLLM answers.
Takeaway
Trustworthy AI is not just about giving fast answers, it is about knowing when a claim is wrong.
Why This Matters Beyond Benchmarks
As AI systems are used more widely, trust becomes essential. A helpful assistant should not only answer quickly, it should also recognize when a question contains a false assumption.
This work shows that better evaluation and better training can make multimodal AI more dependable in real-world settings, where small details often make the biggest difference.
Further Reading & Reference
If you would like to learn more about reducing hallucinations in multimodal AI systems, check out the full paper and the project page. The work will be presented as an oral presentation at CVPR 2026 (IEEE/CVF Conference on Computer Vision and Pattern Recognition), one of the leading conferences in computer vision and AI research.
FINER: MLLMs Hallucinate under Fine-grained Negative Queries.
CVPR 2026 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Denver, CO, USA, Jun 03-07, 2026. Oral Presentation. To be published. Preprint available. arXiv GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work. Get in touch with us to present your paper.
Related

31.07.2026
Benedikt Wiestler: We Want to Build a Time Machine
MCML PI Benedikt Wiestler explains how AI models help to develop specific strategies in clinical therapy for brain tumor patients.

28.07.2026
Gaps in the Benchmark: Why Medical AI Fails in the Real World
MCML researchers show in Nature Health how dynamic red teaming exposes hidden weaknesses in Medical AI beyond static benchmarks.

26.07.2026
Barbara Plank Becomes President of the Association for Computational Linguistics
MCML PI Barbara Plank becomes President of the Association for Computational Linguistics, the world's leading NLP organization.

