19.02.2026

COSMOS – Teaching Vision-Language Models to Look Beyond the Obvious
MCML Research Insight - With Sanghwan Kim, Rui Xiao, Mariana-Iuliana Georgescu, Stephan Alaniz, and Zeynep Akata
Today’s AI systems are remarkably good at recognizing what stands out most. Yet understanding how details relate to each other remains surprisingly difficult. Imagine asking an AI assistant to describe a crowded street photo. It quickly mentions the car in the foreground — but misses the cyclist waiting at the light or the small sign that changes the meaning of the moment.
Key Insight
AI often captures the obvious first — but meaning lives in the relationships between details.
MCML Junior Members Sanghwan Kim, Rui Xiao and former members Mariana-Iuliana Georgescu and Stephan Alaniz, and MCML PI Zeynep Akata address this challenge in their work on COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-Training, presented at CVPR 2025. Their approach explores how AI can learn from both the big picture and fine-grained context to connect images and language more thoughtfully.
The Idea Behind the Paper
Most modern vision–language models learn by comparing entire images with entire captions. This strategy has enabled impressive progress, but it can overlook subtle context. Smaller objects, background actions, or nuanced descriptions may not influence the model’s understanding enough when everything is treated as a single unit.
COSMOS starts from a simple question: What if AI learned from both the whole scene and the smaller pieces inside it? Instead of focusing only on overall similarity, the research encourages models to explore how individual image regions relate to individual parts of language — shifting from surface matching toward deeper understanding.
Core Idea
Understanding emerges when models learn to connect parts, not just compare wholes.
Teaching AI to See in Context
Rather than designing a completely new architecture, the researchers rethought how existing models learn. The training setup works a bit like a classroom:
- A teacher model focuses on stable, high-level understanding.
- A student model explores finer details by looking at smaller image regions and individual sentences.
A key ingredient is cross-attention, which allows visual information and language to guide each other during training. In simple terms, the model learns to ask which words describe a specific part of an image — and which visual details support a sentence. You can think of it like watching a film with subtitles, where each line of dialogue connects to a precise moment on screen.
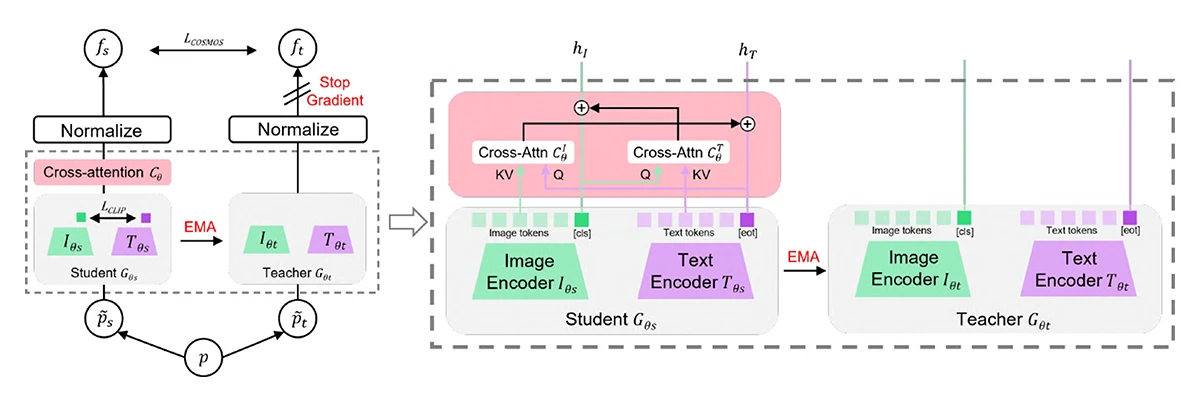
©Kim et al.
Figure 1: An overview of COSMOS. Left: The VLM pre-training mechanism is based on the student-teacher framework with contrastive loss for multi-modal alignment, and cross-modality self-distillation loss for fine-grained representation learning. Right: The architecture of the student and teacher model with cross-attention modules that extract cross-modality information from the student.
Key Findings & Results
This change in training strategy led to noticeable improvements. Models trained with COSMOS became better at recognizing subtle details and distinguishing scenes that look similar but carry different meanings. Importantly, these gains did not come from simply scaling model size or adding more data — they came from improving how the model learns.

©Kim et al.
Figure 2: Qualitative results. Visualization of attention map in cross-attention modules. Attention weights are normalized between 0 and 1.
Takeaway
Sometimes innovation in AI is not about building bigger systems — but about helping them learn to pay attention.
Why This Matters
As AI systems become part of everyday tools — from accessibility features and search engines to creative applications — understanding context becomes increasingly important. Missing small visual cues can lead to inaccurate descriptions or misleading outputs.
COSMOS reflects a broader shift in AI research: progress is not only about building larger models, but also about designing smarter ways for machines to learn. By helping AI connect images and language more precisely, this work moves technology toward more reliable and nuanced understanding.
Further Reading & Reference
If you would like to learn more about how COSMOS connects visual details and language through smarter training strategies, you can explore the full paper presented at CVPR 2025 — one of the leading international conferences in computer vision.
COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

23.03.2026
MCML at EACL 2026
MCML researchers are represented with 13 papers at EACL 2026 (9 Main, and 4 Findings).

