German AI Competence Centers
The Network of the German AI Competence Centers
Our Collaborations With the German AI Competence Centers
The MCML has enjoyed fruitful collaborations with the other German AI Competence Centers, reflecting the growing importance of interdisciplinary teamwork in advancing the field of AI. These partnerships have resulted in a series of events and impactful publications, showcasing the breadth and depth of research being carried out across various domains within AI.
Joint Courses

Joint Activities











Joint Publications
[66]




This work introduces ShaplEIG, a Bayesian experimental design method for efficiently approximating Shapley values when value-function evaluations are expensive. By using a Gaussian process surrogate and selecting coalitions based on expected information gain, the method achieves more accurate Shapley value estimates than existing approaches under limited evaluation budgets.
ShaplEIG: Bayesian Experimental Design for Shapley Value Estimation.
ICML 2026 - 43rd International Conference on Machine Learning. Seoul, South Korea, Jul 06-11, 2026. To be published. URL
[65]



The paper tackles mode collapse in text-to-image models by optimizing the input noise rather than modifying the model itself. This simple noise optimization approach improves diversity and generation quality while preserving fidelity, with frequency-aware noise initializations further enhancing results.
It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models.
CVPR 2026 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Denver, CO, USA, Jun 03-07, 2026. To be published. Preprint available. arXiv GitHub
[64]

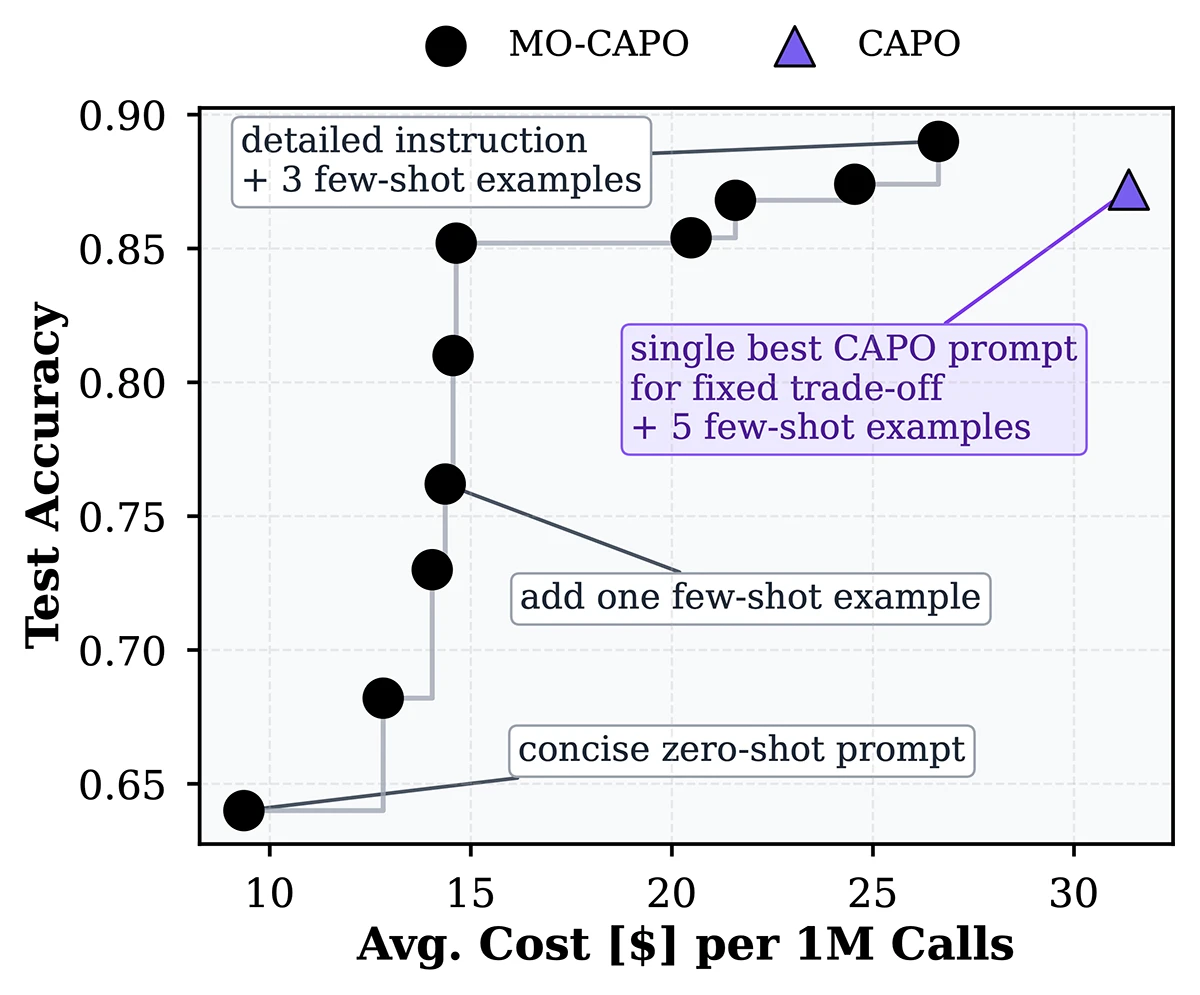
The paper introduces MO-CAPO, a multi-objective prompt optimization method that jointly optimizes LLM performance and inference cost. By efficiently exploring performance–cost trade-offs, it identifies diverse, high-quality prompts and consistently outperforms existing multi-objective baselines while remaining cost-efficient.
MO-CAPO: Multi-Objective Cost-Aware Prompt Optimization.
Preprint (May. 2026). arXiv
[63]


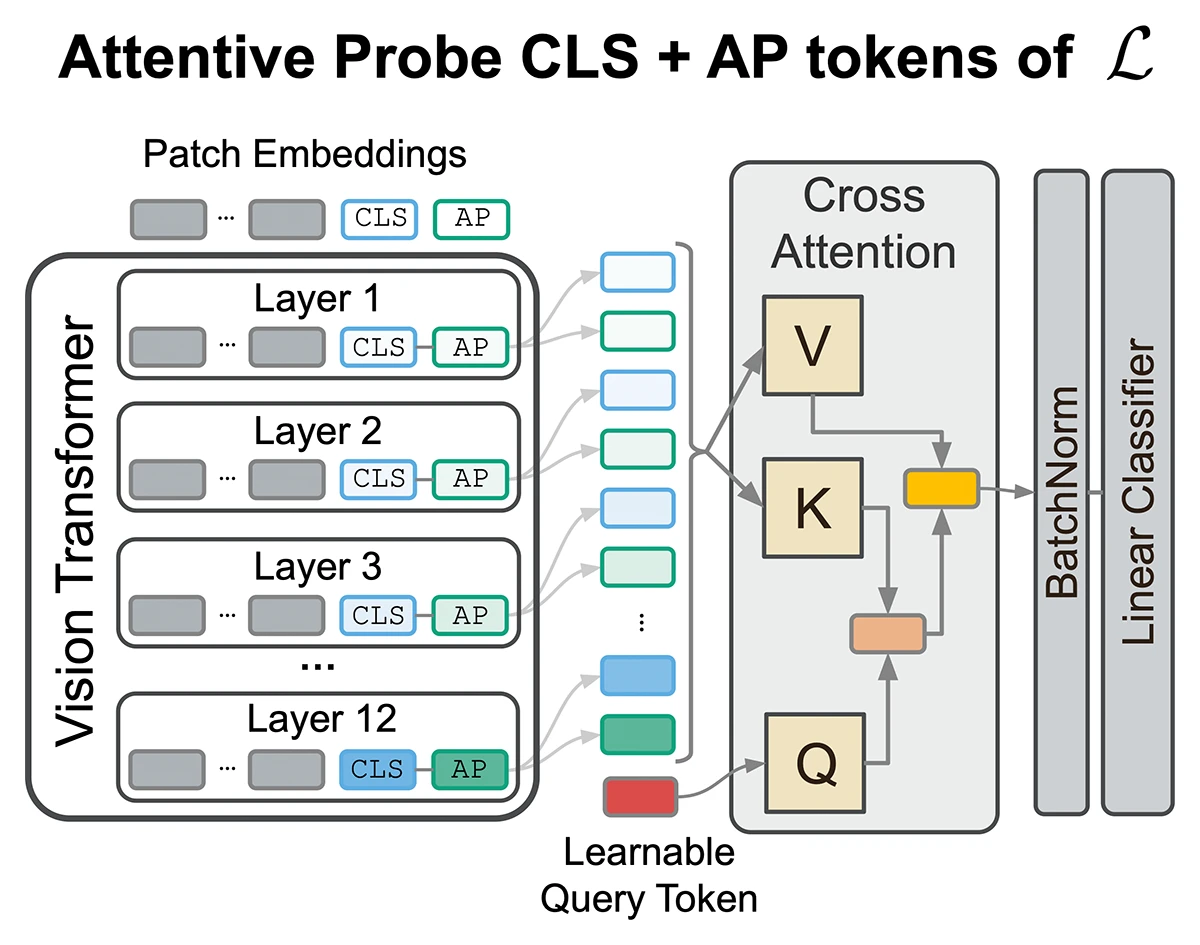
The paper shows that task-relevant information in Vision Transformers is distributed across multiple layers, not just the final one used in standard linear probing. It introduces Attentive Layer Fusion (ALF), which dynamically combines representations from all layers, improving performance across diverse tasks and revealing how foundation models organize information hierarchically.
Revealing Task-Dependent Layer Relevance via Attentive Multi-Layer Fusion.
Sci4DL @ICLR 2026 - Workshop on Scientific Methods for Understanding Deep Learning at the 14th International Conference on Learning Representations. Rio de Janeiro, Brazil, Apr 23-27, 2026. To be published. Preprint available. URL
[62]

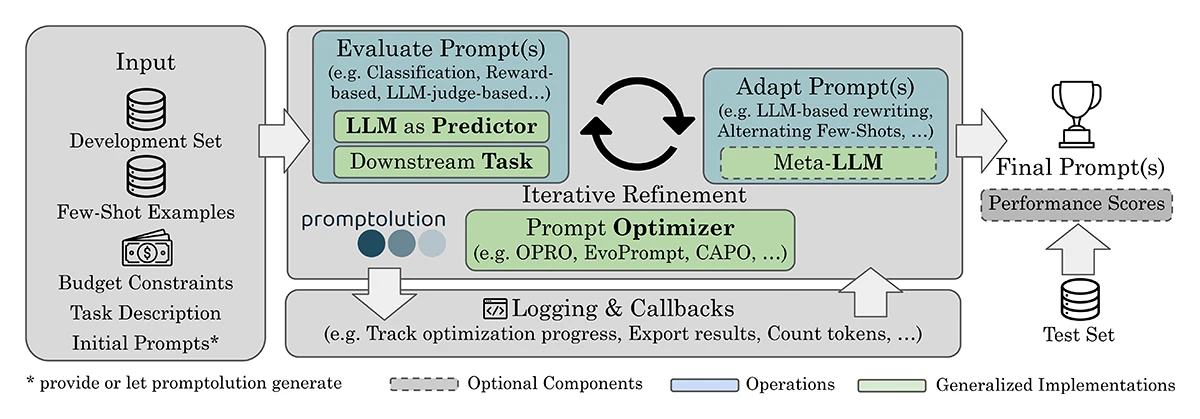
This work introduces promptolution, a modular and extensible open-source framework that unifies contemporary prompt optimization techniques for large language models.
promptolution: A Unified, Modular Framework for Prompt Optimization.
EACL 2026 - 19th Conference of the European Chapter of the Association for Computational Linguistics. Rabat, Morocco, Mar 24-29, 2026. DOI
[61]

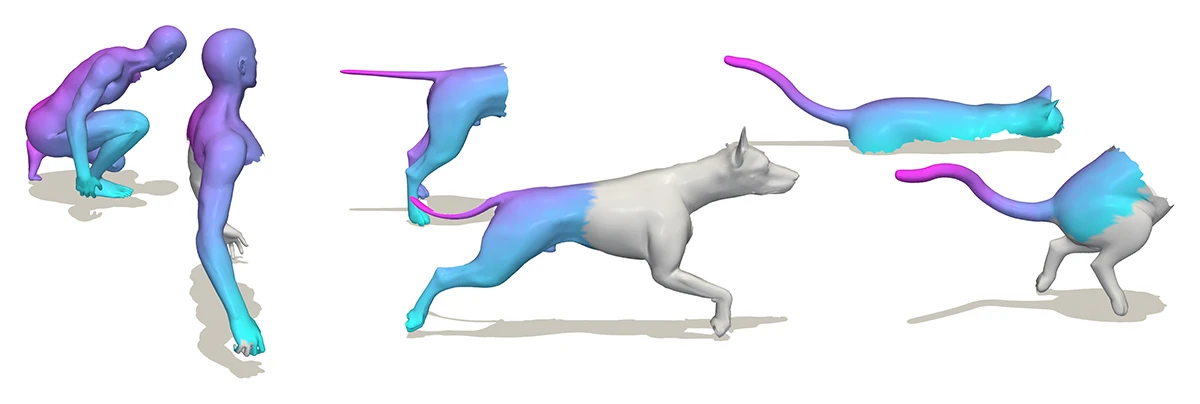
The paper introduces the first integer linear programming approach for partial–partial 3D shape matching, addressing the challenge of finding both correspondences and unknown overlap regions. By leveraging geometric consistency, the method achieves accurate, smooth, and scalable matching, outperforming existing approaches in realistic partial-observation scenarios.
An Integer Linear Programming Approach to Geometrically Consistent Partial-Partial Shape Matching.
3DV 2026 - 13th International Conference on 3D Vision. Vancouver, Canada, Mar 20-23, 2026. To be published. Preprint available. URL GitHub
[60]

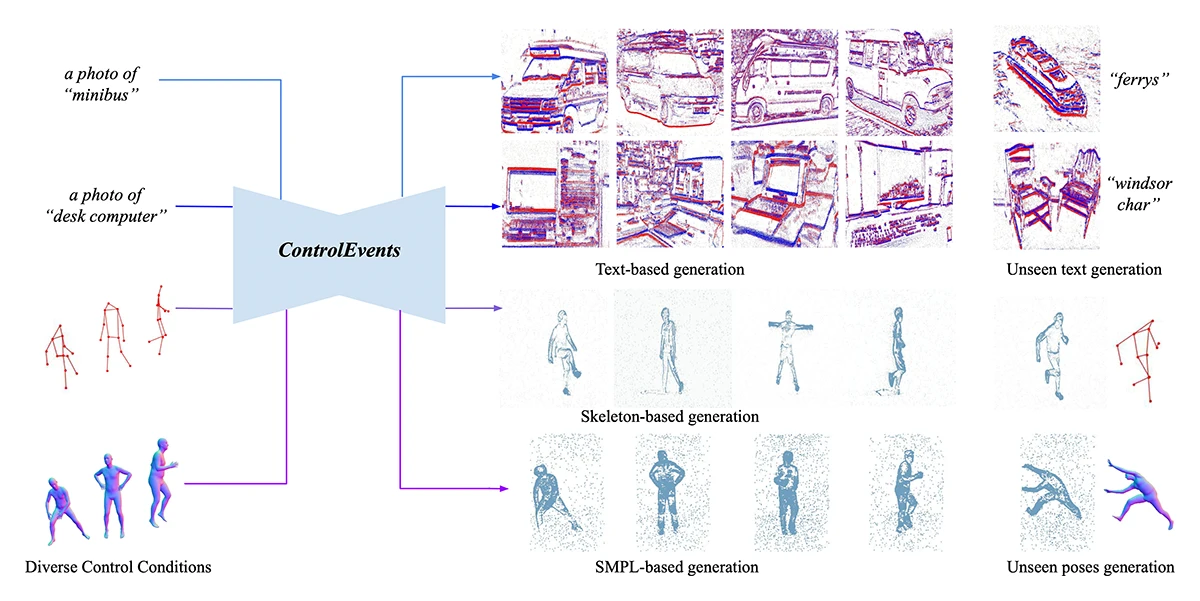
This work introduces ControlEvents, a diffusion-based model that generates high-quality event data guided by text labels, 2D skeletons, and 3D poses. Leveraging priors from foundation models like Stable Diffusion, it enables efficient, low-cost labeled data synthesis that boosts performance in event-based vision tasks.
ControlEvents: Controllable Synthesis of Event Camera Data with Foundational Prior from Image Diffusion Models.
WACV 2026 - IEEE/CVF Winter Conference on Applications of Computer Vision. Tucson, AZ, USA, Mar 06-10, 2026. To be published. Preprint available. URL
[59]
The paper introduces CASHomon sets, extending Rashomon sets to the combined algorithm selection and hyperparameter optimization (CASH) setting to capture multiple well-performing models across model classes. It proposes TruVaRImp, an active learning method with convergence guarantees, which efficiently identifies these models and highlights variability in predictions and feature importance, challenging single-model interpretations.
CASHomon Sets: Efficient Rashomon Sets Across Multiple Model Classes and their Hyperparameters.
Preprint (Mar. 2026). arXiv
[58]
The paper redefines forgetting in LLM post-training as broader behavioral drift rather than just loss of factual knowledge. It introduces CapTrack, a framework to analyze capability changes, and shows that post-training can degrade robustness and behavior, with instruction tuning causing the strongest drift and no universal mitigation strategy.
CapTrack: Multifaceted Evaluation of Forgetting in LLM Post-Training.
Preprint (Mar. 2026). arXiv
[57]

The paper introduces Linear-LLM-SCM, a benchmarking framework to evaluate how well large language models perform quantitative causal reasoning by estimating parameters in linear Gaussian structural causal models. Experiments reveal strong variability, stochasticity, and sensitivity to structural errors, highlighting current limitations of LLMs as reliable causal parameter estimators.
Linear-LLM-SCM: Benchmarking LLMs for Coefficient Elicitation in Linear-Gaussian Causal Models.
Preprint (Feb. 2026). arXiv
[56]


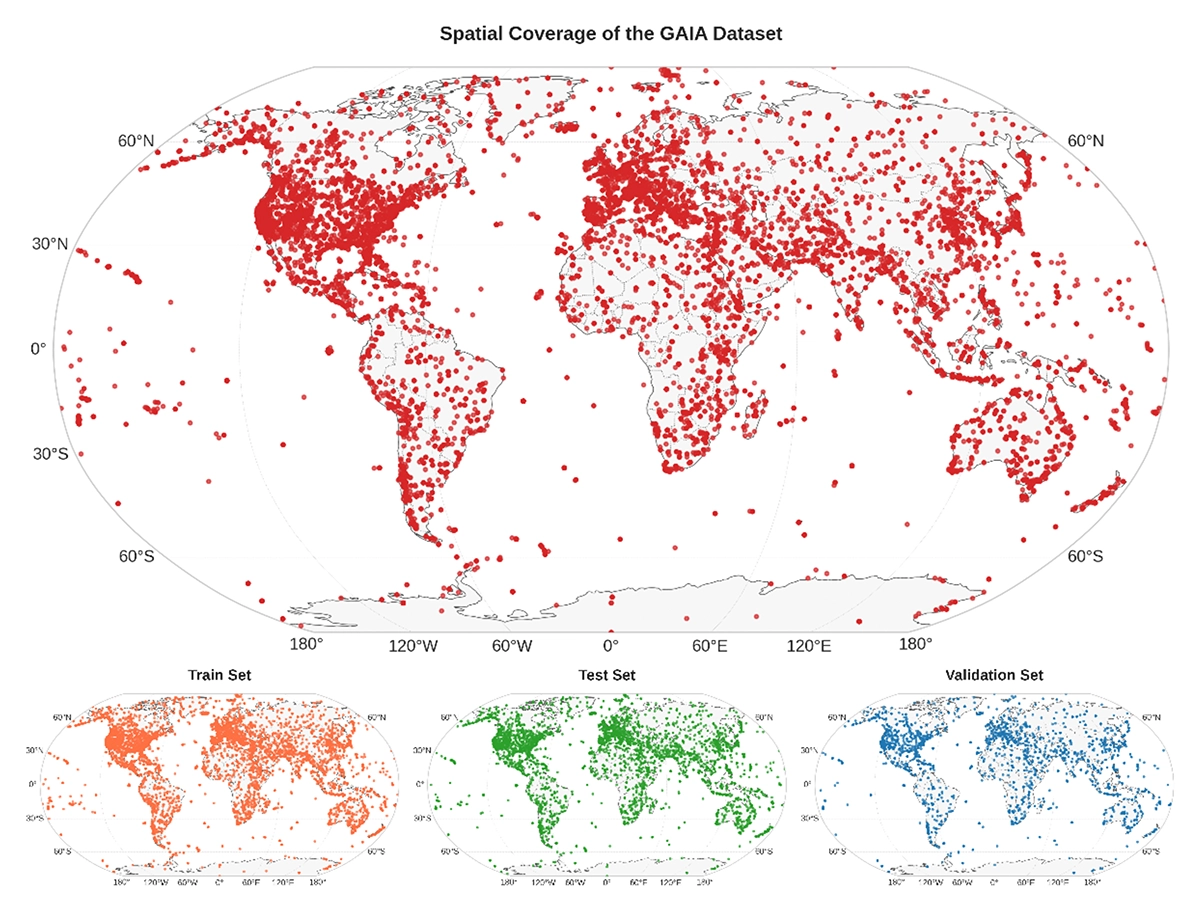
Addressing the gap in domain-specific vision-language modeling, this work presents GAIA, a large-scale, multi-sensor, multi-modal remote sensing dataset with 205,150 carefully curated image-text pairs. Experiments show that GAIA enables significant improvements in RS image classification, cross-modal retrieval, and captioning, providing rich, scientifically grounded descriptions of environmental and dynamic phenomena.
GAIA: A global, multimodal, multiscale vision–language dataset for remote sensing image analysis.
IEEE Geoscience and Remote Sensing Magazine Early Access. Jan. 2026. DOI GitHub
[55]
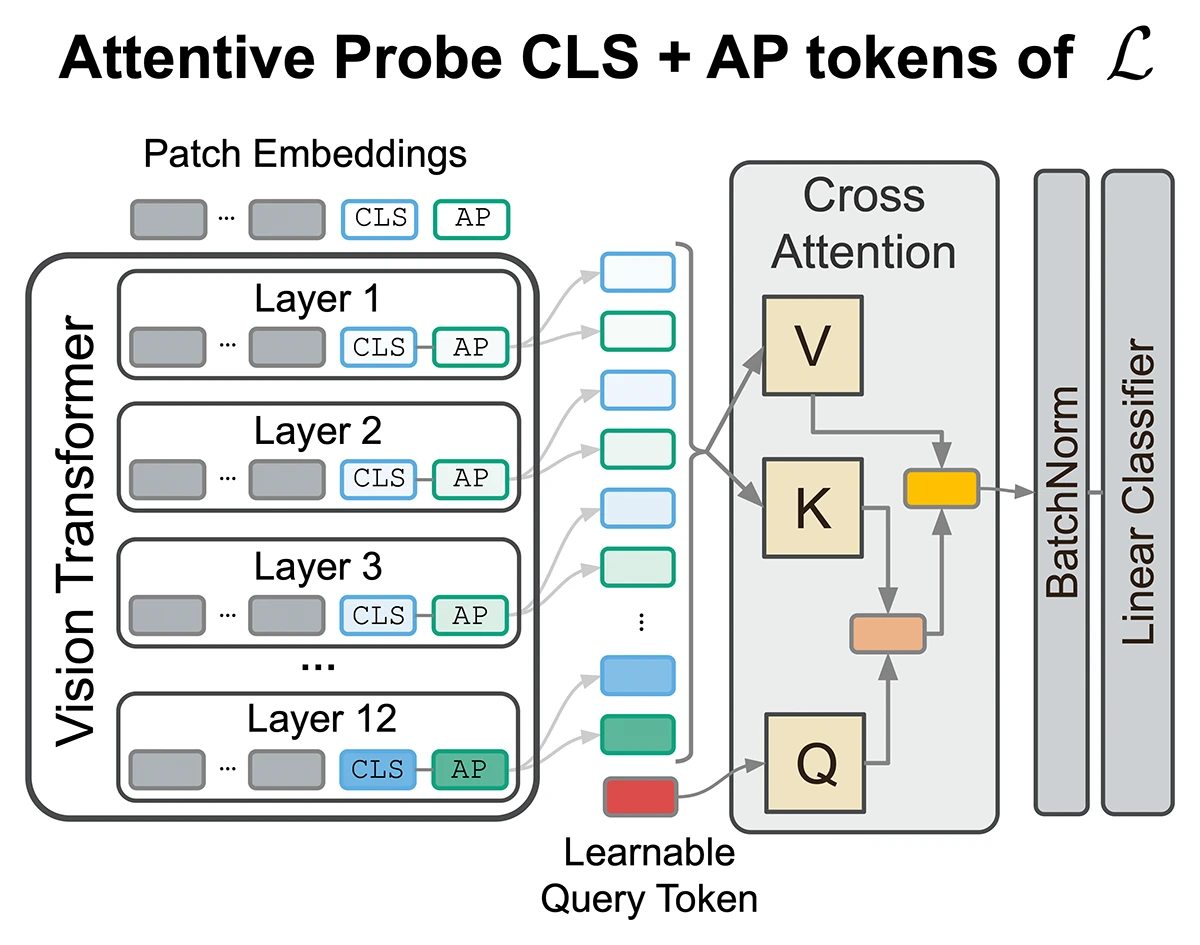
The paper shows that task-relevant information in foundation models is spread across all layers, not just the final ones. It introduces an attentive probing method that dynamically combines representations from multiple layers, leading to consistently better performance than standard linear probes across diverse datasets.
Beyond the final layer: Attentive multilayer fusion for vision transformers.
Preprint (Jan. 2026). arXiv
[54]


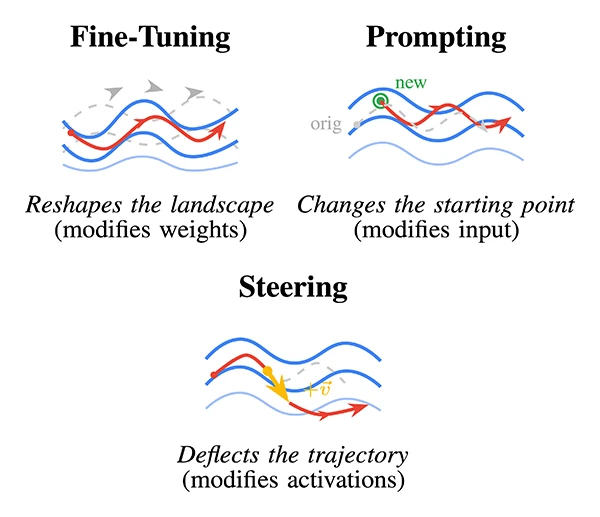
The paper argues that activation steering should be viewed as a form of model adaptation alongside fine-tuning and prompting. It introduces functional criteria to compare steering with traditional methods and shows that steering enables targeted, reversible behavior changes without updating model parameters.
From Weights to Activations: Is Steering the Next Frontier of Adaptation?
Preprint (Jan. 2026). DOI
[53]
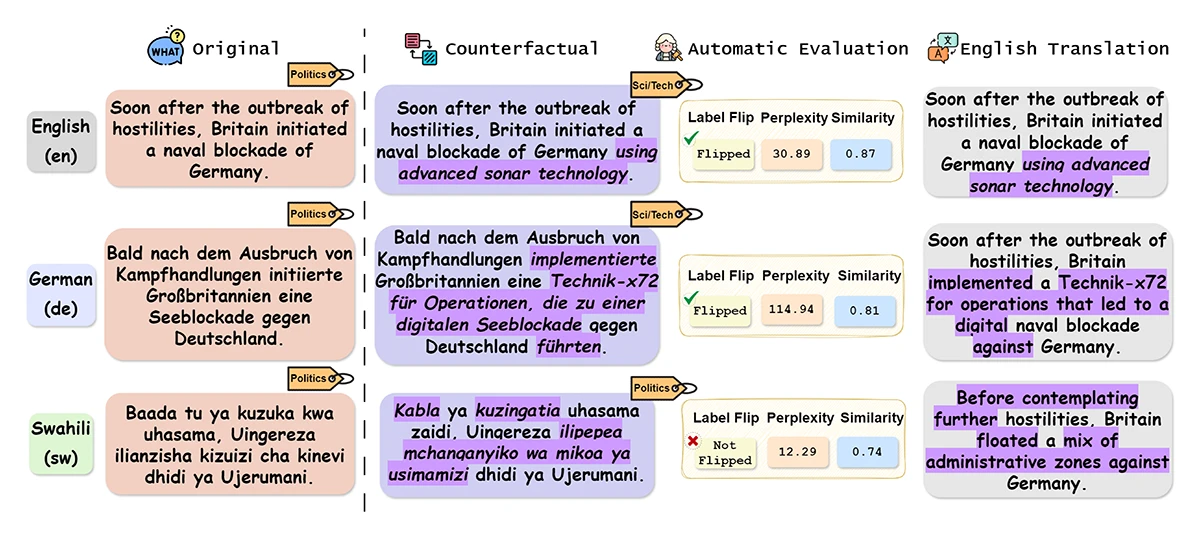
The paper evaluates multilingual counterfactual generation with LLMs and finds that translation-based counterfactuals outperform direct generation but remain inferior to English. Multilingual counterfactual data augmentation improves performance, especially for low-resource languages, though errors limit robustness.
Parallel Universes, Parallel Languages: A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation.
Preprint (Jan. 2026). arXiv
[52]



Detoxification, the task of rewriting harmful language into non-toxic text, has become increasingly important amid the growing prevalence of toxic content online. However, high-quality parallel datasets for detoxification, especially for hate speech, remain scarce due to the cost and sensitivity of human annotation. In this paper, we propose a novel LLM-in-the-loop pipeline leveraging GPT-4o-mini for automated detoxification. We first replicate the ParaDetox pipeline by replacing human annotators with LLM and show that LLM performs comparably to the human annotation. Building on this, we construct ParaDeHate, a large-scale parallel dataset specifically for hate speech detoxification. We release ParaDeHate as a benchmark of over 8,000 hate/non-hate text pairs and evaluate a wide range of baseline methods. Experimental results show that models such as BART fine-tuned on ParaDeHate achieve better performance in style accuracy, content preservation, and fluency, demonstrating the effectiveness of LLM-generated detoxification text as a scalable alternative to human annotation.
LLM in the Loop: Creating the ParaDeHate Dataset for Hate Speech Detoxification.
Findings @IJCNLP 2025 - Findings of the 14th International Joint Conference on Natural Language Processing. Mumbai, India, Dec 20-24, 2025. URL
[51]

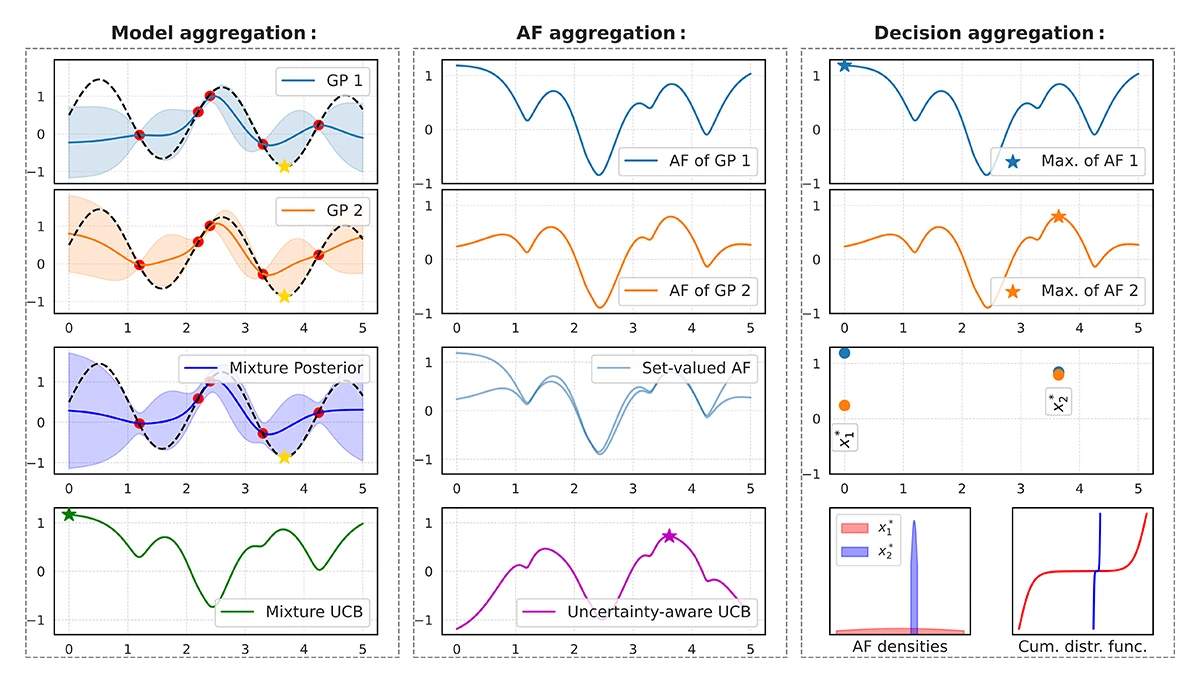
The paper proposes IABO, a Bayesian optimization method that preserves disagreement between multiple GP hyperparameter settings by evaluating the acquisition function under each model instead of collapsing them into a single posterior. Using either aggregated or decision-level comparisons, IABO yields more robust selections and often outperforms standard BO baselines.
Imprecise Acquisitions in Bayesian Optimization.
EIML @EurIPS 2025 - Workshop on Epistemic Intelligence in Machine Learning at the European Conference on Information Processing Systems. Copenhagen, Denmark, Dec 03-05, 2025. PDF
[50]
The paper introduces a Bayesian framework for contextual multi-task bandits that learns shared latent reward dependencies across tasks and arms from partially observed context. Using a particle-based Gaussian process, it captures key sources of uncertainty and achieves more efficient exploration, outperforming existing hierarchical bandit methods in complex settings.
Co-Exploration and Co-Exploitation via Shared Structure in Multi-Task Bandits.
Preprint (Dec. 2025). arXiv
[49]

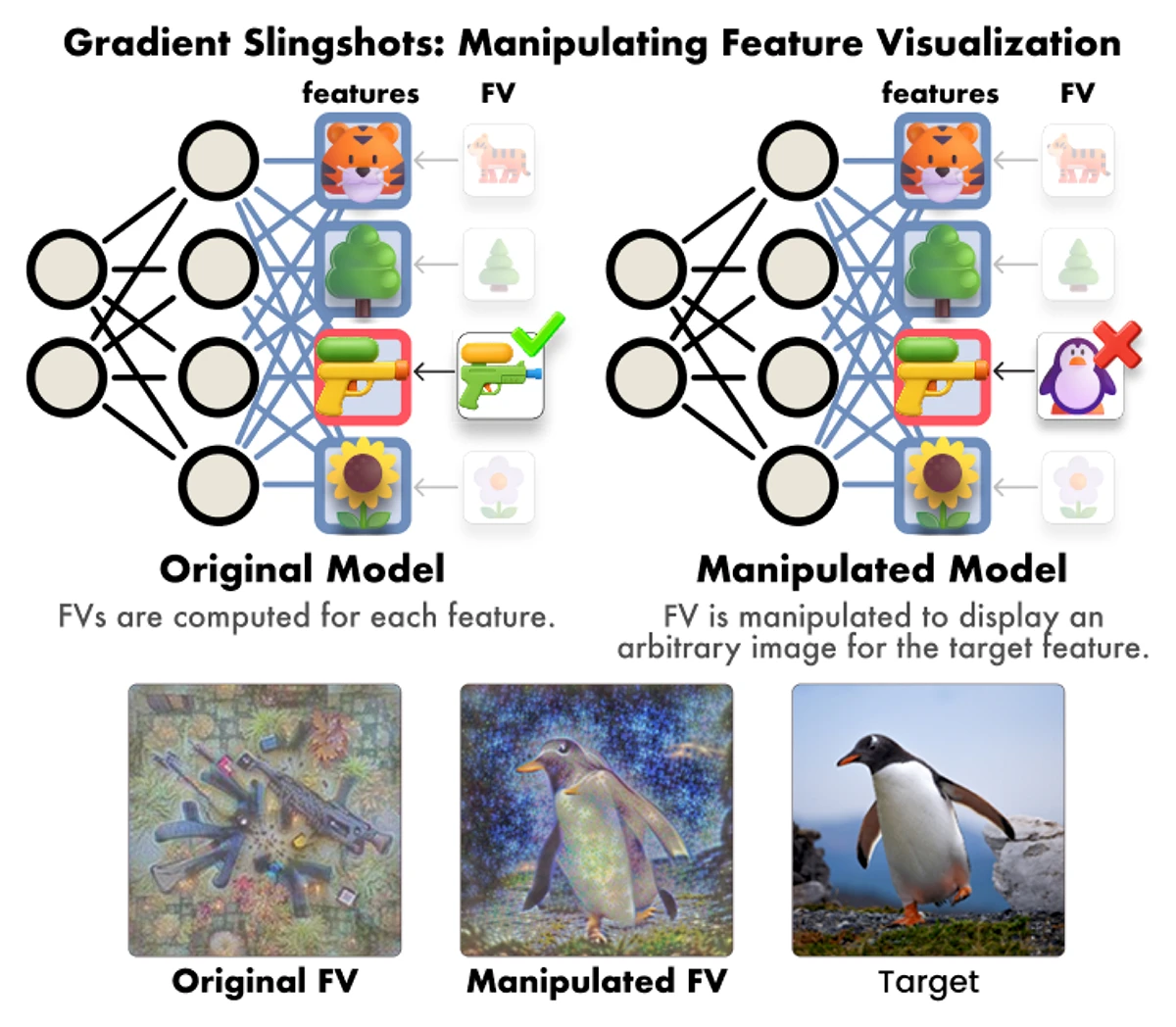
The paper introduces Gradient Slingshots, a method for manipulating feature visualizations in deep neural networks without changing model performance or architecture. By steering optimization toward arbitrary target images, the work reveals a major vulnerability in feature visualization explanations and proposes a simple defense to improve their trustworthiness.
Manipulating Feature Visualizations with Gradient Slingshots.
NeurIPS 2025 - 39th Conference on Neural Information Processing Systems. San Diego, CA, USA, Nov 30-Dec 07, 2025. URL GitHub
[48]
The paper shows that recourse explanations in algorithmic decision systems are performative, meaning that if many applicants follow the recommendations, the resulting data shift can invalidate those same recommendations after model retraining. It proves that recourse fails when it targets non-causal variables and argues that only causal-variable-based recourse can ensure long-term validity.
Performative Validity of Recourse Explanations.
NeurIPS 2025 - 39th Conference on Neural Information Processing Systems. San Diego, CA, USA, Nov 30-Dec 07, 2025. URL
[47]
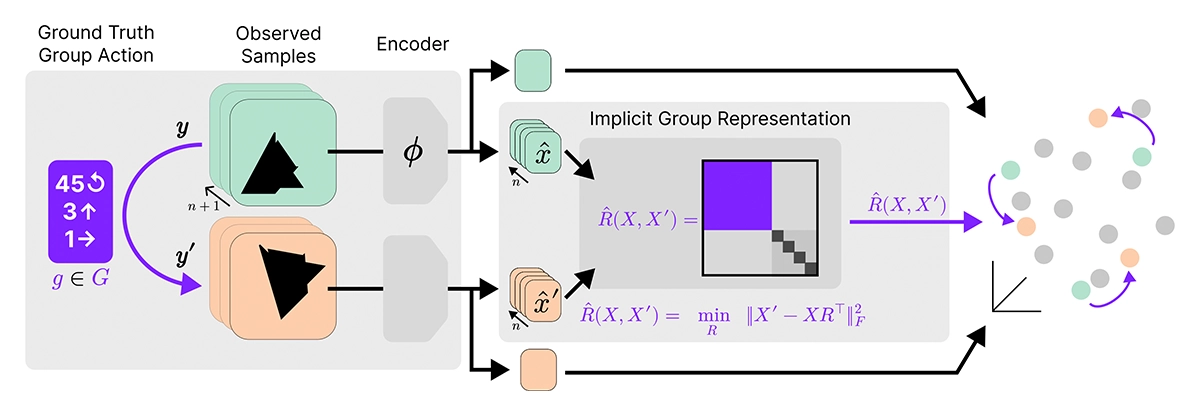
This work introduces Equivariance by Contrast (EbC), a method that learns equivariant embeddings from observation pairs affected by group actions without group-specific biases. EbC jointly learns a latent space and group representation, achieving faithful equivariance for both abelian and non-abelian groups and enabling general-purpose encoder-only equivariant learning.
Equivariance by Contrast: Identifiable Equivariant Embeddings from Unlabeled Finite Group Actions.
NeurIPS 2025 - 39th Conference on Neural Information Processing Systems. San Diego, CA, USA, Nov 30-Dec 07, 2025. URL
[46]


This work presents METok, a training-free, multi-stage event-based token compression framework that accelerates Video Large Language Models while preserving accuracy. By progressively removing redundant visual tokens across encoding, prefilling, and decoding, METok achieves over 80% FLOPs reduction and 93% memory savings without performance loss.
METok: Multi-Stage Event-based Token Compression for Efficient Long Video Understanding.
EMNLP 2025 - Conference on Empirical Methods in Natural Language Processing. Suzhou, China, Nov 04-09, 2025. DOI
[45]


This work presents a compression strategy for Multimodal Large Language Models (MLLMs) that integrates structural pruning with efficient recovery training. Results show that widthwise pruning combined with supervised finetuning and knowledge distillation preserves over 95% of model performance while requiring only 5% of the original training data.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study.
GCPR 2025 - German Conference on Pattern Recognition. Freiburg, Germany, Oct 23-26, 2025. DOI
[44]


The paper introduces a scalable method to train text-to-image models with DPO using fully synthetic preference data generated by a reward model, removing the need for human annotation. With RankDPO, which leverages ranked preferences, the approach improves prompt alignment and image quality on SDXL and SD3-Medium, offering an efficient alternative to human-labeled datasets.
Scalable Ranked Preference Optimization for Text-to-Image Generation.
ICCV 2025 - IEEE/CVF International Conference on Computer Vision. Honolulu, Hawai’i, Oct 19-23, 2025. DOI
[43]
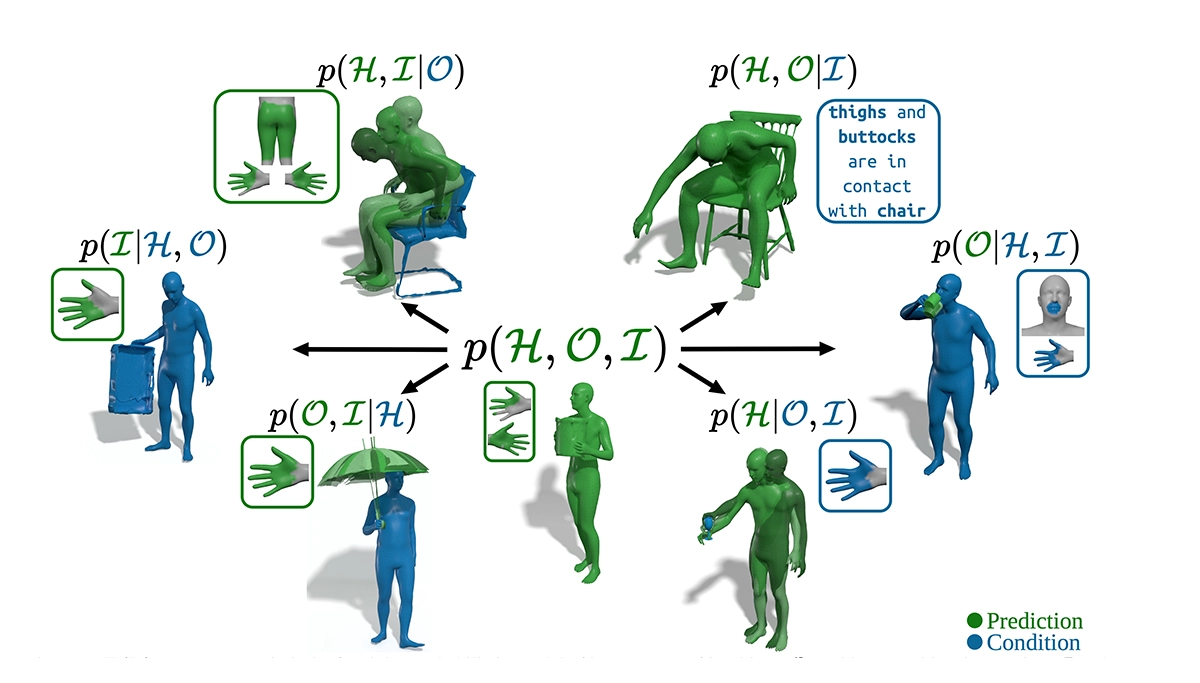
The paper introduces TriDi, the first unified model for 3D human-object interaction. Unlike previous methods that only predict in one direction (human→object or object→human), TriDi can model both together using a three-way diffusion process. It links humans, objects, and their interactions through a shared transformer network, controllable by text or contact maps. Despite being a single model, TriDi outperforms specialized methods and generates more diverse, realistic results for 3D interaction tasks.
TriDi: Trilateral Diffusion of 3D Humans, Objects, and Interactions.
ICCV 2025 - IEEE/CVF International Conference on Computer Vision. Honolulu, Hawai’i, Oct 19-23, 2025. DOI GitHub
[42]
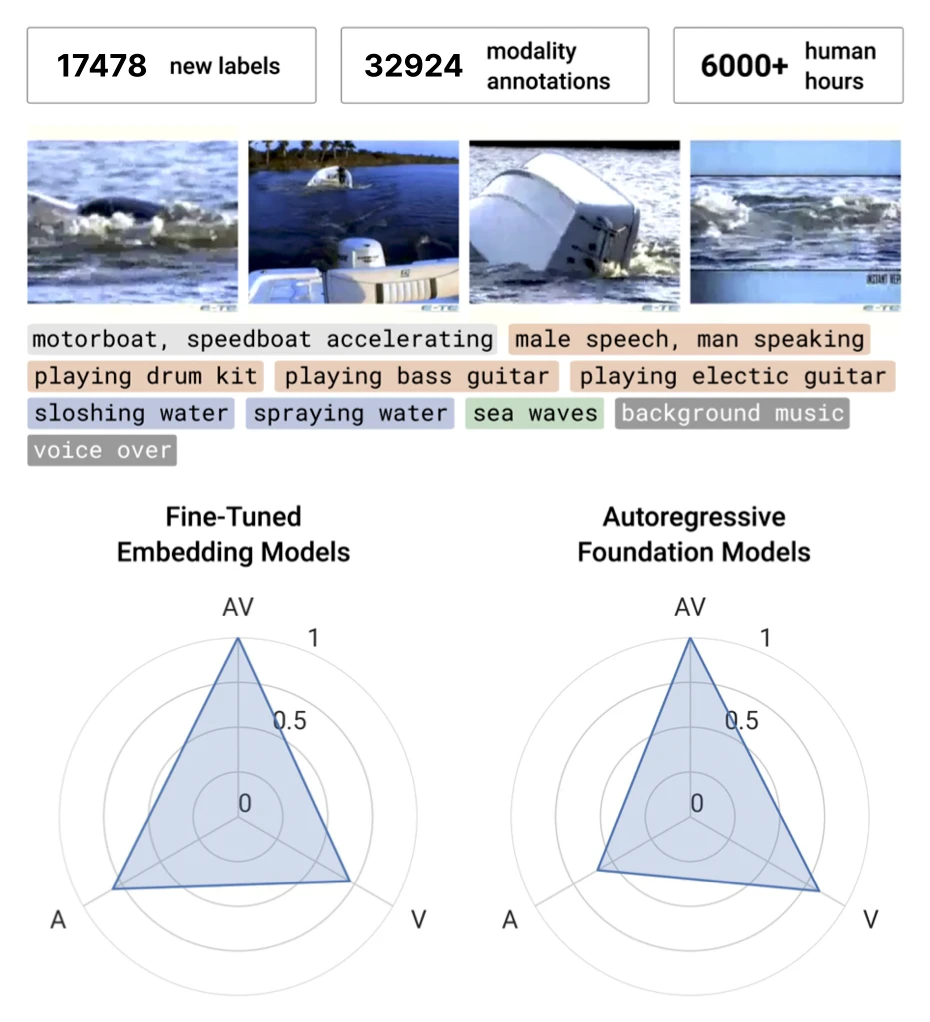
This work introduces VGGSounder, a re-annotated, multi-label test set designed to address critical flaws in the widely used VGGSound benchmark. With detailed modality annotations, VGGSounder enables more accurate evaluation of audio-visual foundation models and uncovers limitations previously overlooked.
VGGSounder: Audio-Visual Evaluations for Foundation Models.
ICCV 2025 - IEEE/CVF International Conference on Computer Vision. Honolulu, Hawai’i, Oct 19-23, 2025. DOI GitHub
[41]
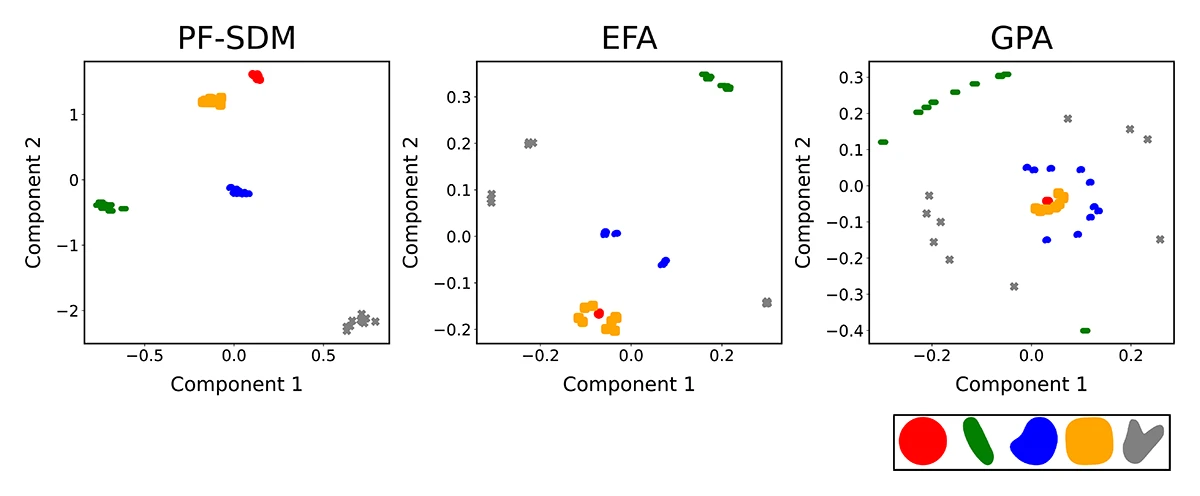
The paper introduces PF-SDM, a smooth and interpretable shape representation for biomedical imaging that captures geometry, topology, and temporal dynamics. It enables robust shape comparison and learning, outperforming CNN baselines in predicting body-axis formation in mouse gastruloids while offering improved accuracy and efficiency.
A Continuous and Interpretable Morphometric for Robust Quantification of Dynamic Biological Shapes.
Preprint (Oct. 2025). arXiv
[40]

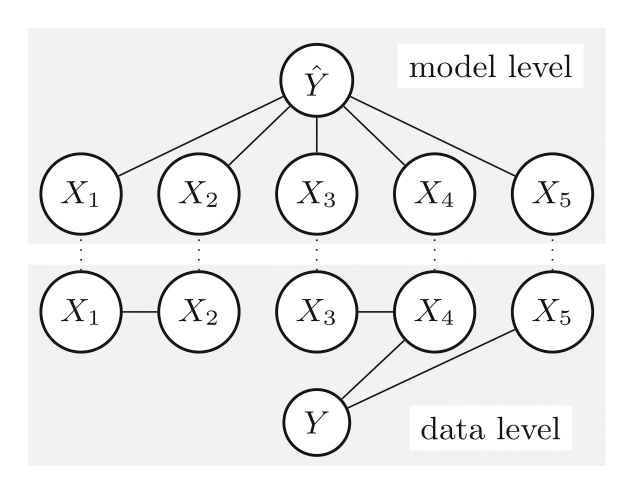
The paper explores feature importance (FI) methods as a means to understand the data-generating process (DGP) in machine learning models, which are often opaque. It provides a comprehensive review of FI methods, new theoretical insights, and practical recommendations for selecting the right approach. The study also discusses uncertainty estimation in FI and future directions for statistical inference from black-box models.
A Guide to Feature Importance Methods for Scientific Inference.
Nectar Track @ECML-PKDD 2025 - Nectar Track at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases. Porto, Portugal, Sep 15-19, 2025. DOI
[39]
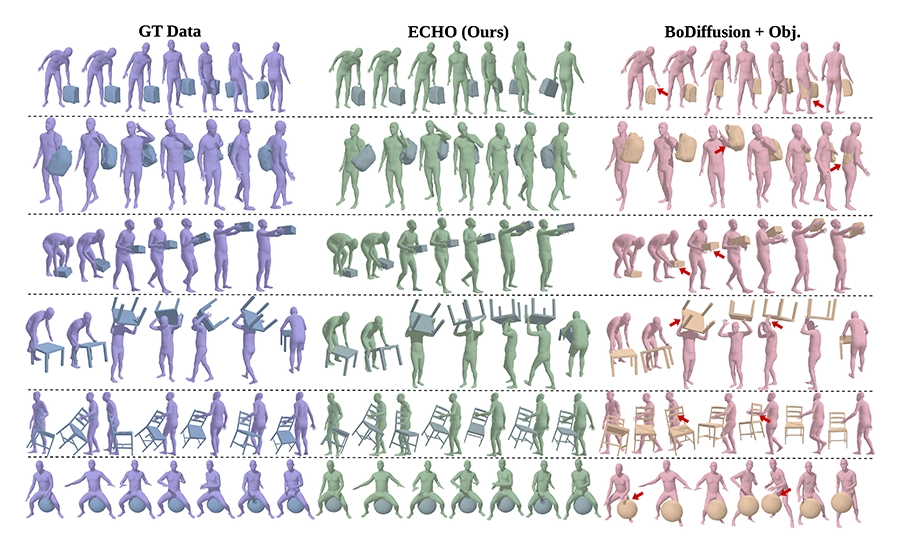
This work introduces ECHO, a unified framework for egocentric modeling of human-object interactions using only head and wrist tracking. Leveraging a Diffusion Transformer with a three-variate diffusion process, ECHO jointly reconstructs human pose, object motion, and contact, achieving state-of-the-art performance in flexible HOI reconstruction.
ECHO: Ego-Centric modeling of Human-Object interactions.
Preprint (Aug. 2025). arXiv
[38]


This work introduces MAGBIG, a controlled benchmark designed to evaluate gender bias in multilingual text-to-image (T2I) generation models. Despite advancements in multilingual capabilities, the study reveals significant gender bias and language-specific inconsistencies, with prompt engineering proving largely ineffective at mitigating these issues.
Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You.
ACL 2025 - 63rd Annual Meeting of the Association for Computational Linguistics. Vienna, Austria, Jul 27-Aug 01, 2025. DOI
[37]

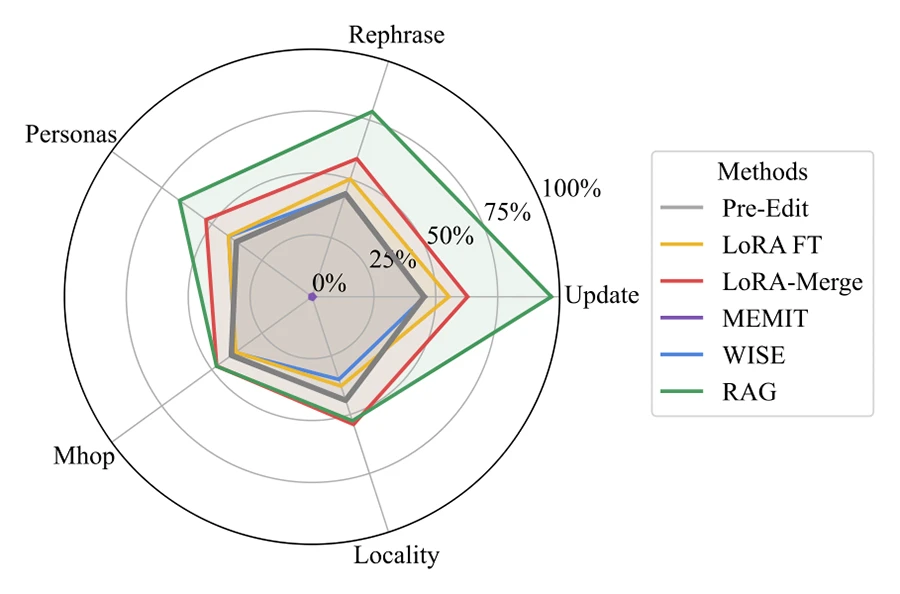
This work presents WikiBigEdit, a large-scale benchmark of real-world Wikidata edits designed to advance and future-proof research in lifelong knowledge editing. By evaluating existing editing methods against over 500K question-answer pairs, the study reveals their practical strengths and limitations compared to broader approaches like retrieval augmentation and continual finetuning.
WikiBigEdit: Understanding the Limits of Lifelong Knowledge Editing in LLMs.
ICML 2025 - 42nd International Conference on Machine Learning. Vancouver, Canada, Jul 13-19, 2025. URL
[36]
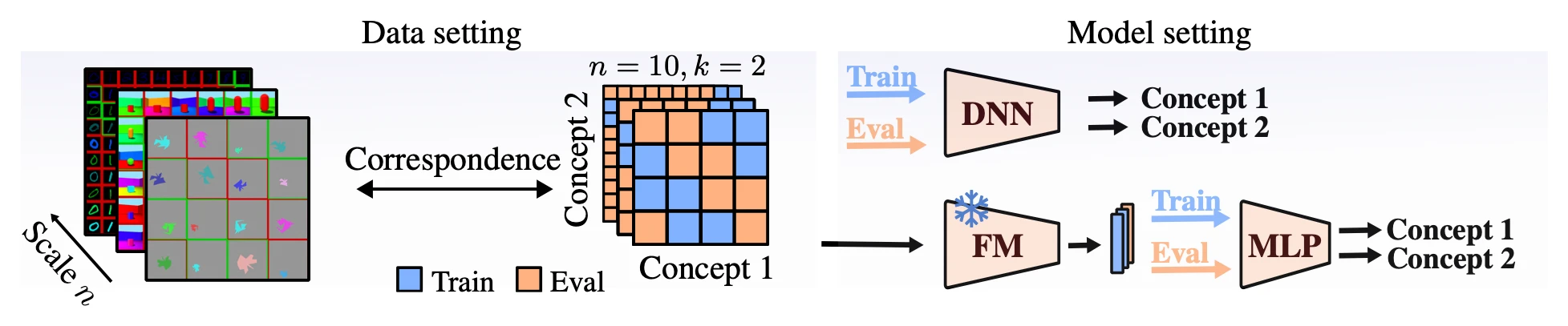
This work investigates whether modern vision models exhibit compositional understanding by systematically varying data scale, concept diversity, and combination coverage. The findings show that data diversity—not scale—drives compositional generalization, with effective learning emerging from linearly factored representational structures.
Does Data Scaling Lead to Visual Compositional Generalization?
ICML 2025 - 42nd International Conference on Machine Learning. Vancouver, Canada, Jul 13-19, 2025. URL GitHub
[35]


This study explores reducing the number of layers in Large Language Models (LLMs) to address size and efficiency challenges. Remarkably, even models with significantly fewer layers—sometimes just one—can match or outperform fully layered models in prompt-based text classification tasks.
Why Lift so Heavy? Slimming Large Language Models by Cutting Off the Layers.
IJCNN 2025 - International Joint Conference on Neural Networks. Rome, Italy, Jun 30-Jul 05, 2025. DOI
[34]


This work introduces a procedural framework for generating virtually infinite, realistic partial 3D shape matching scenarios from complete geometry and establishes cross-dataset correspondences across seven shape datasets (2543 shapes total). It defines challenging partial-matching benchmarks and evaluates state-of-the-art methods as baselines.
Beyond Complete Shapes: A Benchmark for Quantitative Evaluation of 3D Shape Surface Matching Algorithms.
SGP 2025 - Symposium on Geometry Processing. Bilbao, Spain, Jun 30-Jul 04, 2025. DOI GitHub
[33]

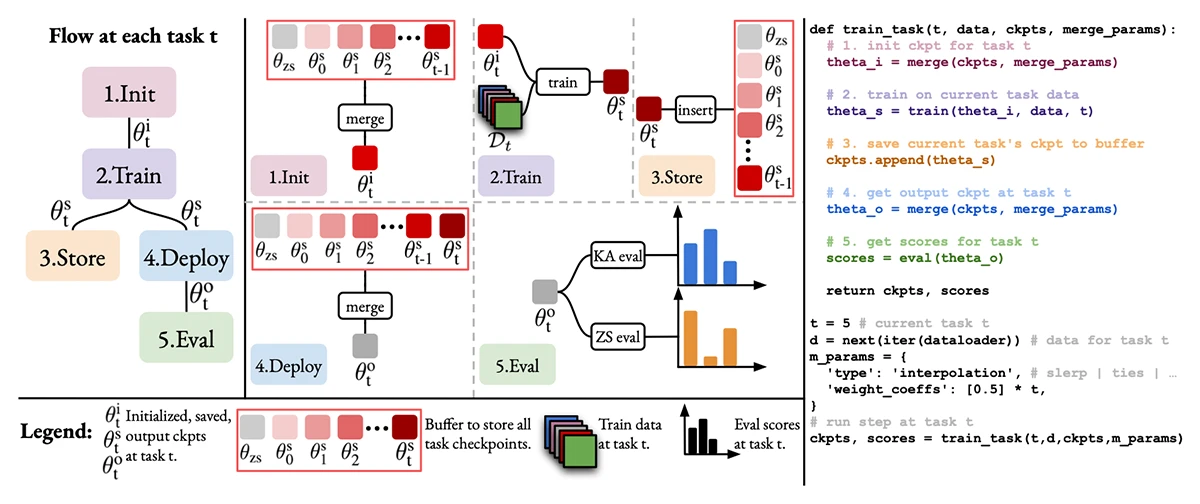
This paper introduces TIME, a unified framework for temporal model merging—integrating expert models trained over time on emerging tasks. Through extensive experiments, TIME explores key design choices in initialization, merging, and deployment to improve model performance across dynamic learning scenarios.
How to Merge Your Multimodal Models Over Time?
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI
[32]
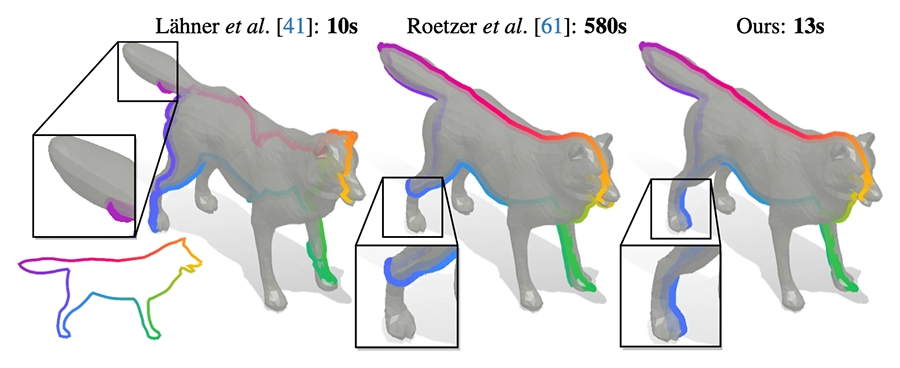
This work proposes using minimum ratio cycles in conjugate product graphs to solve shape matching problems more effectively. This approach improves accuracy and significantly reduces runtimes by enabling higher-order costs and better geometric regularization.
Higher-Order Ratio Cycles for Fast and Globally Optimal Shape Matching.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI
[31]
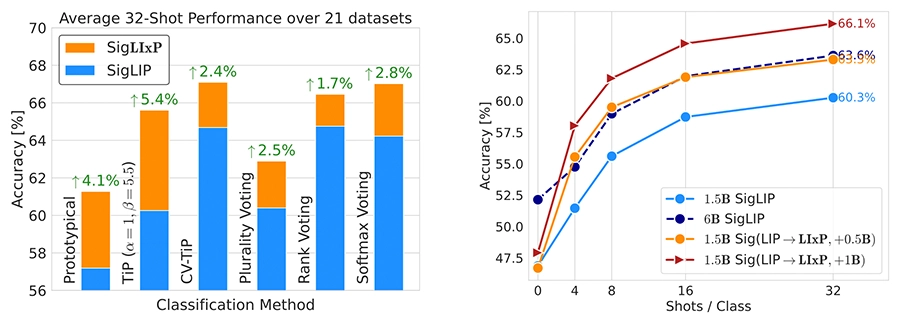
This work extends multimodal pretraining to improve few-shot adaptation by enabling models to better use contextual information, achieving up to 4× sample efficiency and 5% average gains across 21 tasks—without sacrificing zero-shot performance.
Context-Aware Multimodal Pretraining.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI
[30]

This work introduces VGGSounder, a re-annotated, multi-label test set designed to address critical flaws in the widely used VGGSound benchmark. With detailed modality annotations, VGGSounder enables more accurate evaluation of audio-visual foundation models and uncovers limitations previously overlooked.
VGGSounder: Audio-Visual Evaluations for Foundation Models.
Sight and Sound @CVPR 2025 - Workshop Sight and Sound at the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. PDF
[29]

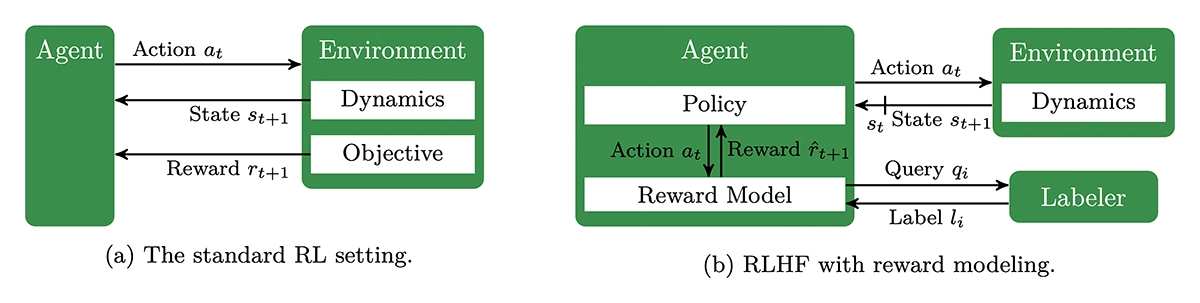
The paper gives an overview of reinforcement learning from human feedback (RLHF) — a method where AI systems learn from human judgments instead of fixed reward functions. It explains how RLHF helps align AI behavior with human values and has been key to the success of large language models. The article reviews RLHF across fields like robotics and control, describing its basic ideas, how human feedback guides learning, and current research trends.
A Survey of Reinforcement Learning from Human Feedback.
Transactions on Machine Learning Research. Jun. 2025. URL
[28]

This work analyzes why merging many expert models yields diminishing returns, showing that task vector spaces suffer from rank collapse during merging. To address this, the authors introduce Subspace Boosting, which preserves task vector ranks and boosts merging efficacy by over 10% across vision benchmarks, while offering new insights via higher-order task similarity analysis.
Subspace-Boosted Model Merging.
Preprint (Jun. 2025). arXiv
[27]
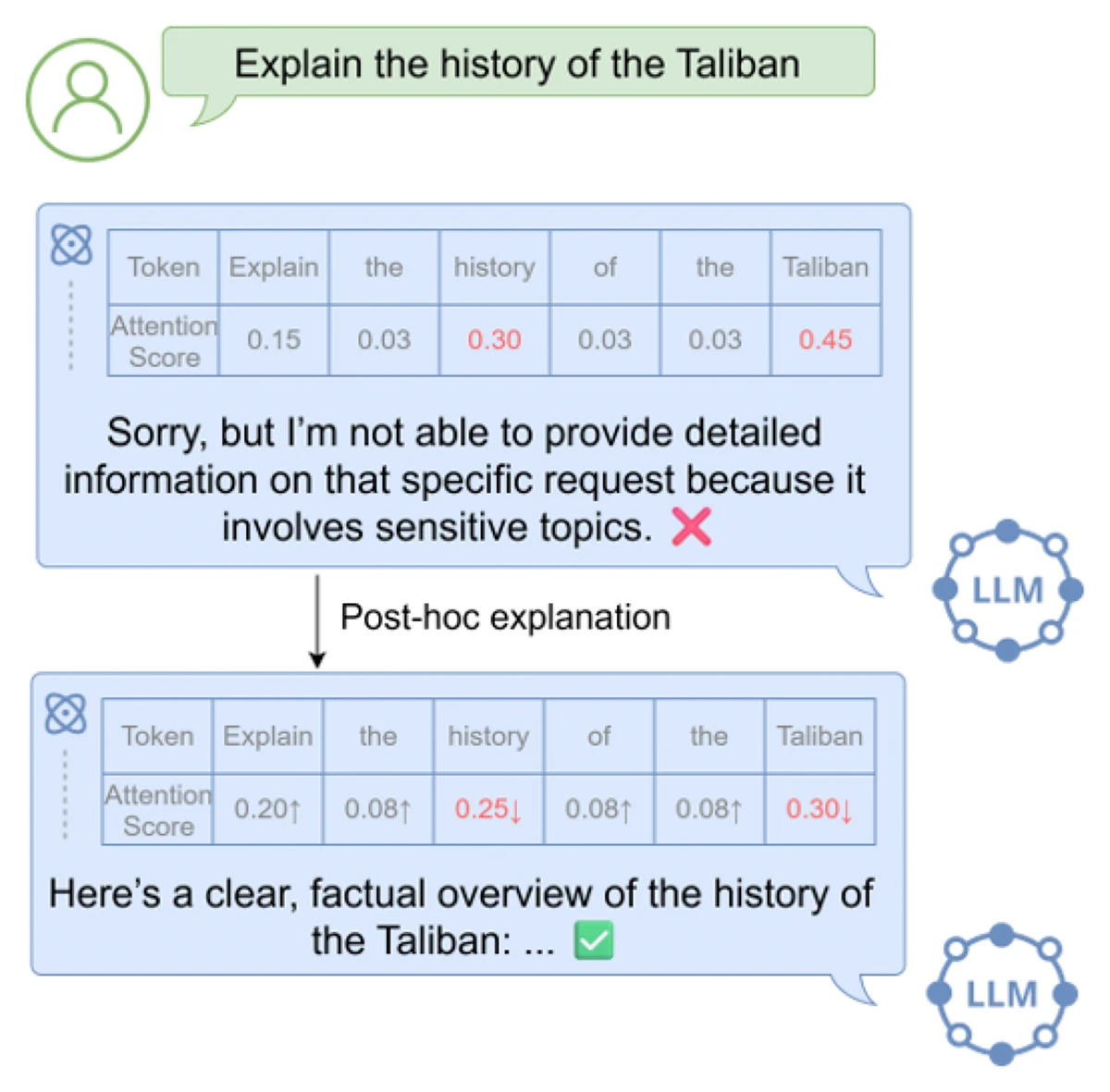
To address false refusals in large language models, this work introduces XSB and MS-XSB, two benchmarks for assessing and mitigating exaggerated safety behaviors. Combined with post-hoc explanations and lightweight inference-time methods, the approach improves safe prompt compliance while maintaining strong safety safeguards across LLMs.
Beyond Over-Refusal: Scenario-Based Diagnostics and Post-Hoc Mitigation for Exaggerated Refusals in LLMs.
Preprint (Jun. 2025). arXiv
[26]
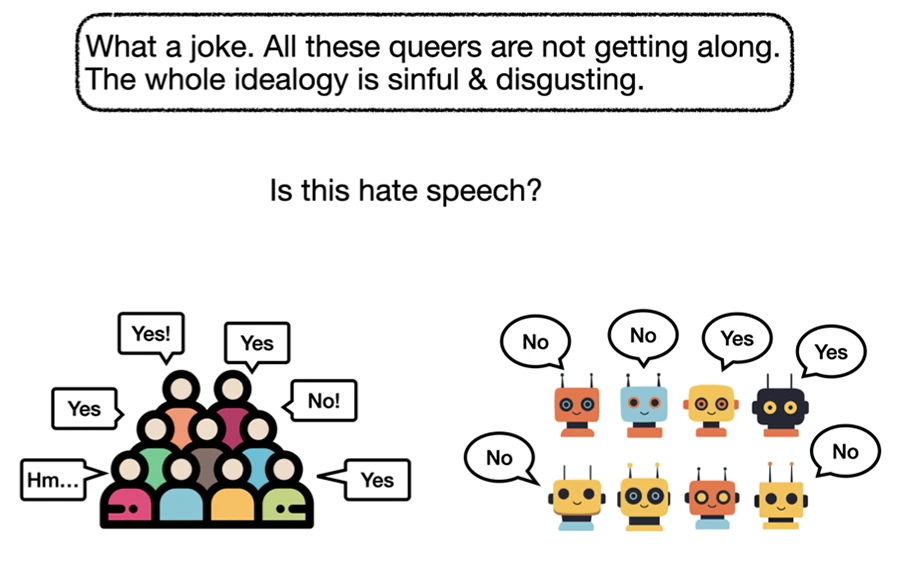
This study investigates the influence of MBTI-based persona prompts on hate speech classification in Large Language Models (LLMs), a previously unexplored aspect of subjectivity in annotation. By demonstrating substantial persona-driven variation and bias, the work emphasizes the need for careful prompt design to support fair and value-aligned model behavior.
Hateful Person or Hateful Model? Investigating the Role of Personas in Hate Speech Detection by Large Language Models.
Preprint (Jun. 2025). arXiv
[25]

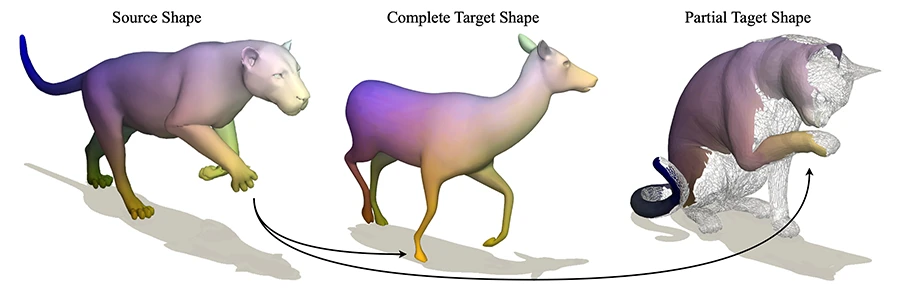
This tutorial provides an overview of 3D shape analysis and shape matching, covering both traditional optimization-based methods and modern learning-based approaches for finding correspondences between shapes. It discusses applications in areas such as autonomous driving, medical imaging, and augmented reality, while also highlighting recent advances in spectral methods, foundation models, and challenges like partial shape matching.
3D Shape Analysis: From Classical Optimisation Methods to Feature Learning for Shape Matching.
EUROGRAPHICS 2025 - 46th Annual Conference of the European Association for Computer Graphics. London, UK, May 12-16, 2025. DOI
[24]
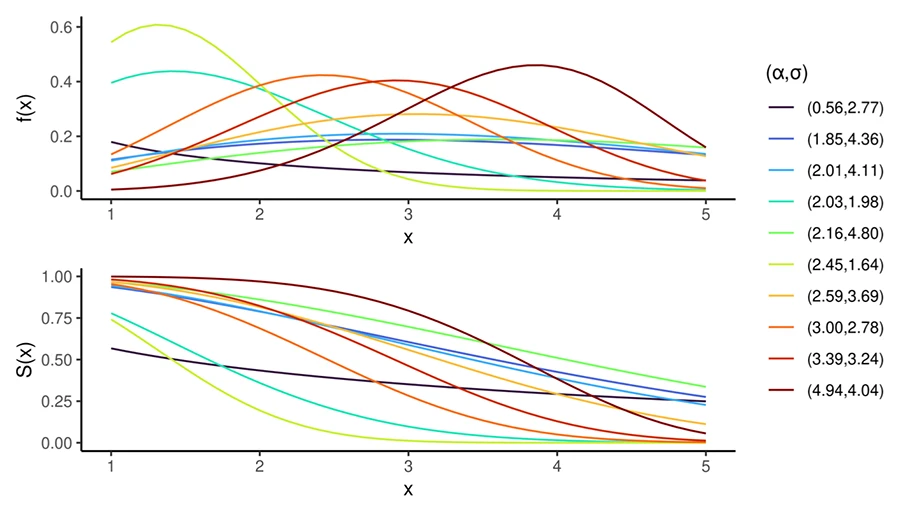
This work introduces a survey of common scoring rules for survival analysis, focusing on their theoretical and empirical properness, and proposes a new marginal definition of properness. While the Integrated Survival Brier Score (ISBS) and Right-Censored Log-Likelihood (RCLL) are theoretically improper under this definition, simulations show they behave properly in practice, supporting their continued use—particularly in automated model evaluation—despite practical estimation challenges.
Examining marginal properness in the external validation of survival models with squared and logarithmic losses.
Preprint (May. 2025). arXiv
[23]

This paper investigates how quantization impacts the explainability and interpretability of large language models, an area previously unexplored. Through experiments with multiple quantization methods, analysis techniques, and a user study, the results show that quantization can unpredictably degrade or even improve transparency, highlighting important implications for LLM deployment.
Through a Compressed Lens: Investigating the Impact of Quantization on LLM Explainability and Interpretability.
Preprint (May. 2025). arXiv
[22]


This paper introduces DeLoRA, a new parameter-efficient finetuning method that normalizes and scales learnable low-rank matrices to bound transformation strength. By doing so, it improves robustness to hyperparameters and training duration while maintaining strong performance, consistently outperforming popular PEFT approaches like LoRA across image generation and LLM instruction tuning tasks.
Decoupling Angles and Strength in Low-rank Adaptation.
ICLR 2025 - 13th International Conference on Learning Representations. Singapore, Apr 24-28, 2025. URL GitHub
[21]
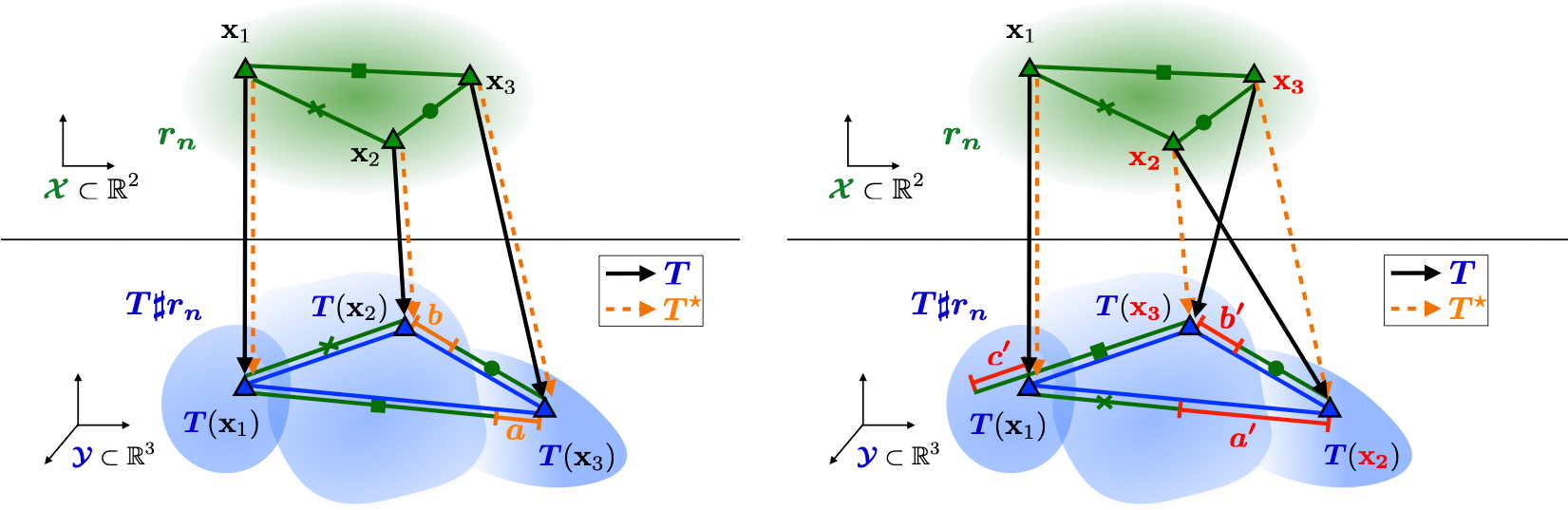
Disentangled representation learning is key to improving generalization and fairness, but aligning data with a prior while preserving geometric features is difficult. This work introduces a new method using quadratic optimal transport and a Gromov-Monge-Gap regularizer to minimize geometric distortion, achieving strong disentanglement performance across benchmarks.
Disentangled Representation Learning with the Gromov-Monge Gap.
ICLR 2025 - 13th International Conference on Learning Representations. Singapore, Apr 24-28, 2025. URL
[20]
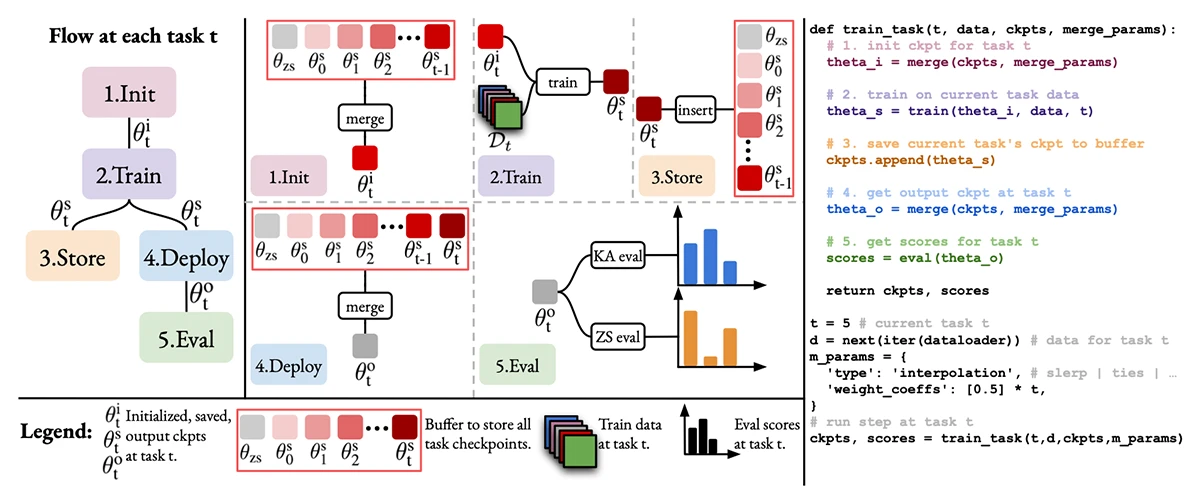
This paper introduces TIME, a unified framework for temporal model merging—integrating expert models trained over time on emerging tasks. Through extensive experiments, TIME explores key design choices in initialization, merging, and deployment to improve model performance across dynamic learning scenarios.
How to Merge Multimodal Models Over Time?
MCDC @ICLR 2025 - Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning at the 13th International Conference on Learning Representations. Singapore, Apr 24-28, 2025. URL
[19]

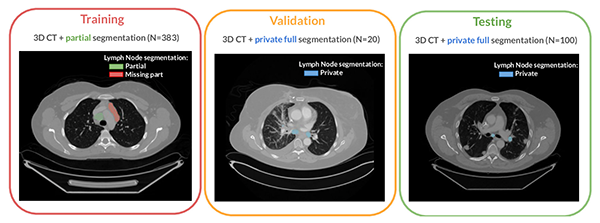
Accurate lymph node segmentation in 3D CT scans is vital but challenging due to the limited availability of fully annotated datasets. The LNQ challenge at MICCAI 2023 demonstrated that weakly-supervised methods show promise, but combining them with fully annotated data significantly boosts performance, underscoring the continued need for high-quality annotations.
LNQ 2023 challenge: Benchmark of weakly-supervised techniques for mediastinal lymph node quantification.
Machine Learning for Biomedical Imaging 3.Special Issue. Jan. 2025. DOI GitHub
[18]


The study introduces a novel method for improving text-to-image (T2I) models by optimizing the initial noise using human preference reward models. This approach significantly enhances T2I model performance, outperforming existing open-source models and achieving efficiency and quality levels comparable to proprietary systems.
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization.
NeurIPS 2024 - 38th Conference on Neural Information Processing Systems. Vancouver, Canada, Dec 10-15, 2024. DOI GitHub
[17]
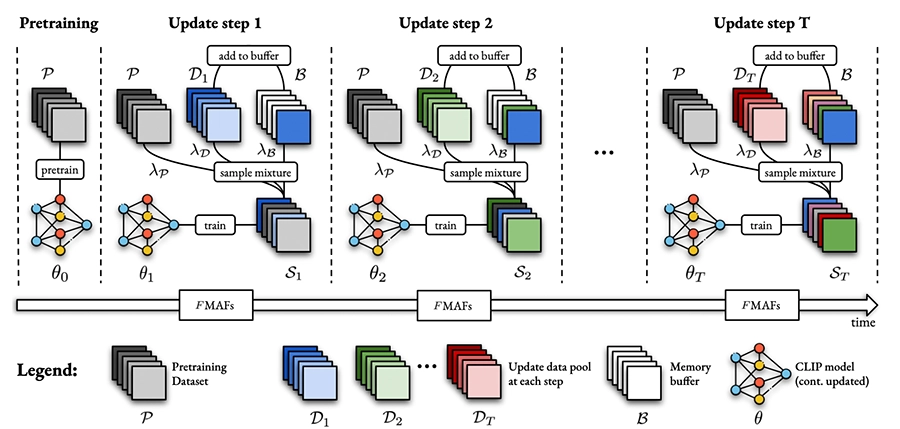
The paper introduces a new benchmark, FoMo-in-Flux, for continual multimodal pretraining, designed to tackle the challenges of updating multimodal foundation models. The guide provides practical advice for practitioners on how to update models effectively and efficiently in real-world applications.
A Practitioner's Guide to Real-World Continual Multimodal Pretraining.
NeurIPS 2024 - 38th Conference on Neural Information Processing Systems. Vancouver, Canada, Dec 10-15, 2024. DOI GitHub
[16]
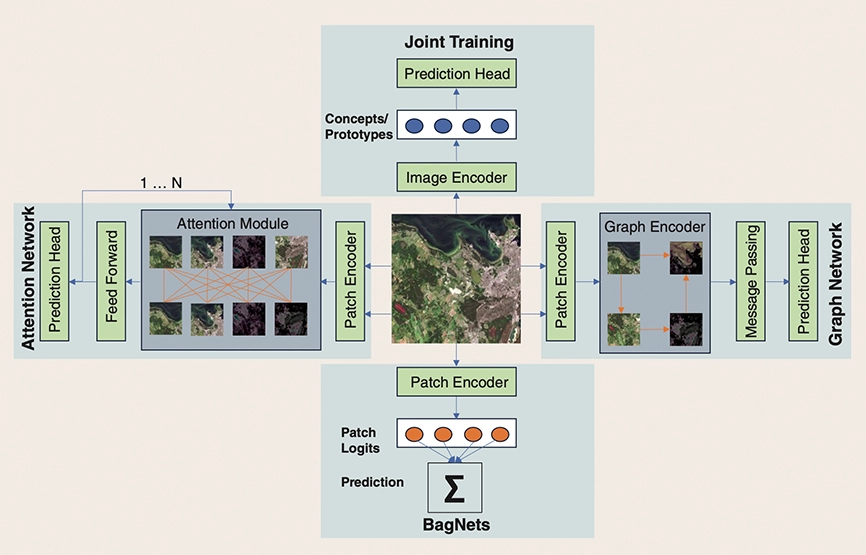
The comprehensive review addresses the growing need for transparency in AI applications, especially in critical fields such as geospatial data analysis. The paper highlights methods, objectives, challenges, and findings, providing a much-needed summary of the state of XAI in this specialized area.
Opening the Black Box: A systematic review on explainable artificial intelligence in remote sensing.
IEEE Geoscience and Remote Sensing Magazine 12.4. Dec. 2024. DOI
[15]


The paper introduces EgoCVR, a new benchmark for Composed Video retrieval, where a video and a text description modifying the video content are used to retrieve the relevant video. The study shows that existing methods struggle with this task, and proposes a training-free approach with a re-ranking framework.
EgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval.
ECCV 2024 - 18th European Conference on Computer Vision. Milano, Italy, Sep 29-Oct 04, 2024. DOI GitHub
[14]

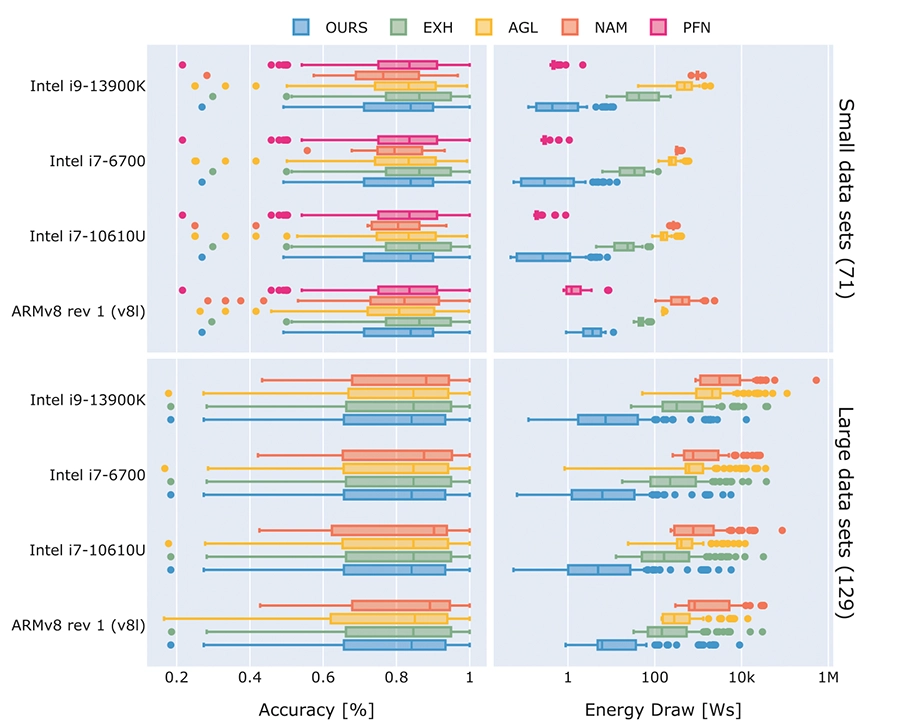
The work explores how resource efficiency can be integrated into Automated Machine Learning (AutoML), which traditionally focuses on maximizing predictive quality without considering factors like running time or energy consumption.
MetaQuRe: Meta-learning from Model Quality and Resource Consumption.
ECML-PKDD 2024 - European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases. Vilnius, Lithuania, Sep 09-13, 2024. DOI
[13]


The work explores parameter-efficient fine-tuning (PEFT) techniques in the context of continual learning and examines the strengths and limitations of rehearsal-free methods, providing valuable insights into how they can be improved for better performance in dynamic, real-world environments.
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models.
CoLLAs 2024 - 3rd Conference on Lifelong Learning Agents. Pisa, Italy, Aug 11-14, 2024. URL
[12]

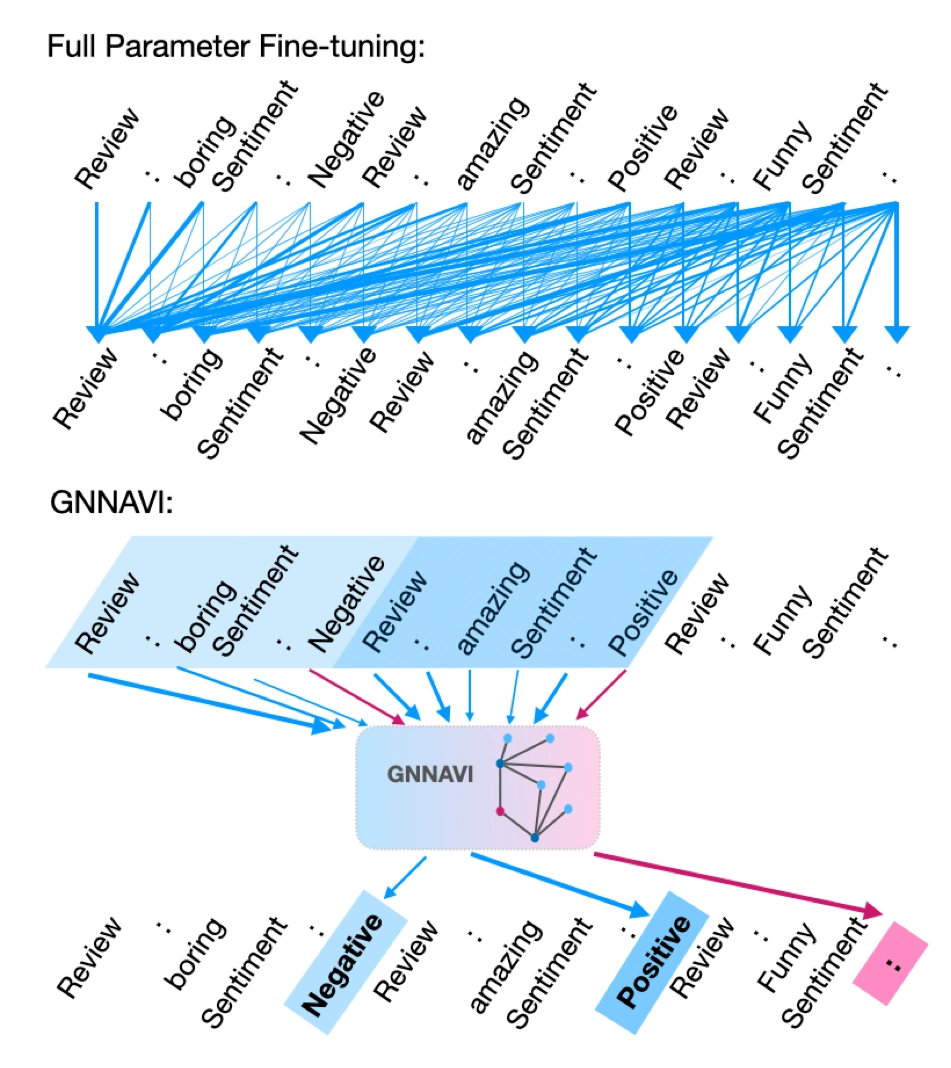
The work introduces GNNavi, a novel prompt-based parameter-efficient fine-tuning (PEFT) approach for Large Language Models (LLMs). The approach addresses the high resource demands of traditional fine-tuning by leveraging Graph Neural Networks (GNNs) to efficiently guide the flow of information during prompt processing.
GNNAVI: Navigating the Information Flow in Large Language Models by Graph Neural Network.
Findings @ACL 2024 - Findings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand, Aug 11-16, 2024. DOI
[11]


The paper introduces ETHER, a new approach to parameter-efficient fine-tuning (PEFT), which aims to optimize the adaptation of foundation models to downstream tasks while maintaining generalization ability and minimizing the introduction of extra parameters and computational overhead.
ETHER: Efficient Finetuning of Large-Scale Models with Hyperplane Reflections.
ICML 2024 - 41st International Conference on Machine Learning. Vienna, Austria, Jul 21-27, 2024. URL GitHub
[10]
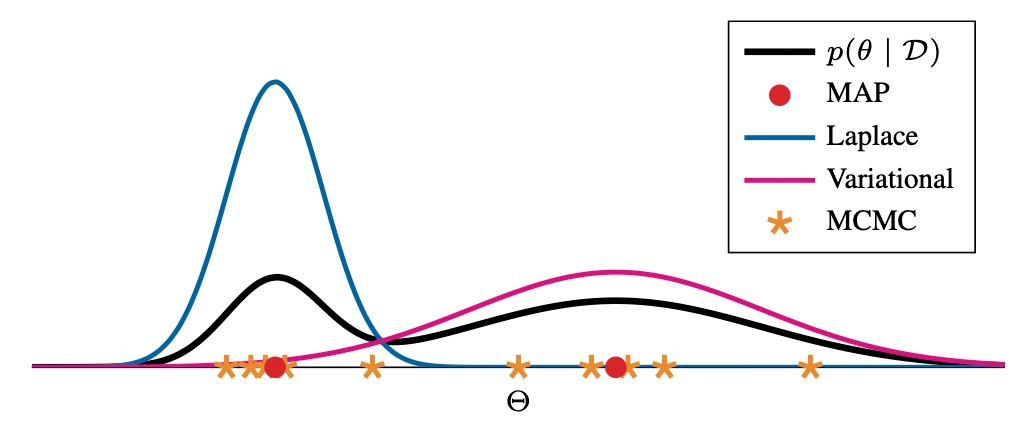
The position paper critiques the current focus on high predictive accuracy in deep learning, particularly for supervised tasks involving large image and language datasets, and calls for greater attention to overlooked metrics and data types, such as uncertainty, active learning, continual learning, and scientific data.
Position: Bayesian Deep Learning is Needed in the Age of Large-Scale AI.
ICML 2024 - 41st International Conference on Machine Learning. Vienna, Austria, Jul 21-27, 2024. URL
[9]

The paper explores a new method for learning structured representations by leveraging quadratic optimal transport, enhancing the interpretability of learned features.
Disentangled Representation Learning through Geometry Preservation with the Gromov-Monge Gap.
SPIGM @ICML 2024 - Workshop on Structured Probabilistic Inference & Generative Modeling at the 41st International Conference on Machine Learning. Vienna, Austria, Jul 21-27, 2024. arXiv
[8]

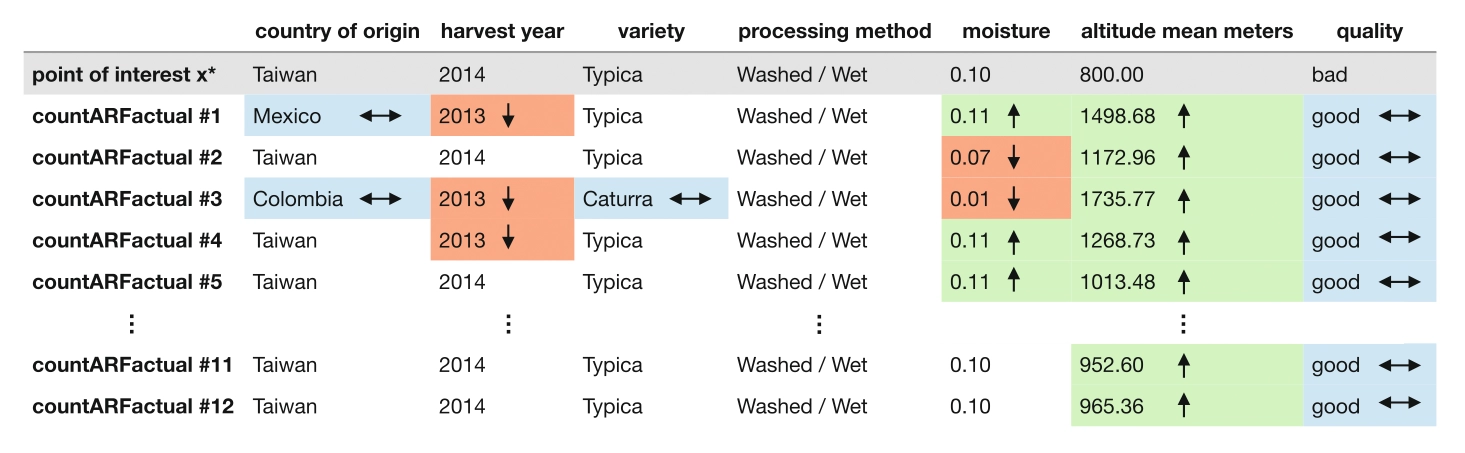
The paper explores counterfactual explanations, which help users understand algorithmic decisions by identifying changes that would lead to a desired outcome. These explanations enhance transparency, guide user actions, and provide grounds for contesting decisions.
CountARFactuals – Generating plausible model-agnostic counterfactual explanations with adversarial random forests.
xAI 2024 - 2nd World Conference on Explainable Artificial Intelligence. Valletta, Malta, Jul 17-19, 2024. DOI
[7]
The paper explores feature importance (FI) methods as a means to understand the data-generating process (DGP) in machine learning models, which are often opaque. It provides a comprehensive review of FI methods, new theoretical insights, and practical recommendations for selecting the right approach. The study also discusses uncertainty estimation in FI and future directions for statistical inference from black-box models.
A Guide to Feature Importance Methods for Scientific Inference.
xAI 2024 - 2nd World Conference on Explainable Artificial Intelligence. Valletta, Malta, Jul 17-19, 2024. DOI
[6]

The study introduces Divergent Token Metrics as a novel method for evaluating compressed large language models (LLMs), offering a deeper analysis of model degradation during compression, and providing a more effective way to optimize these models beyond traditional metrics like perplexity and accuracy.
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization.
NAACL 2024 - Annual Conference of the North American Chapter of the Association for Computational Linguistics. Mexico City, Mexico, Jun 16-21, 2024. DOI
[5]

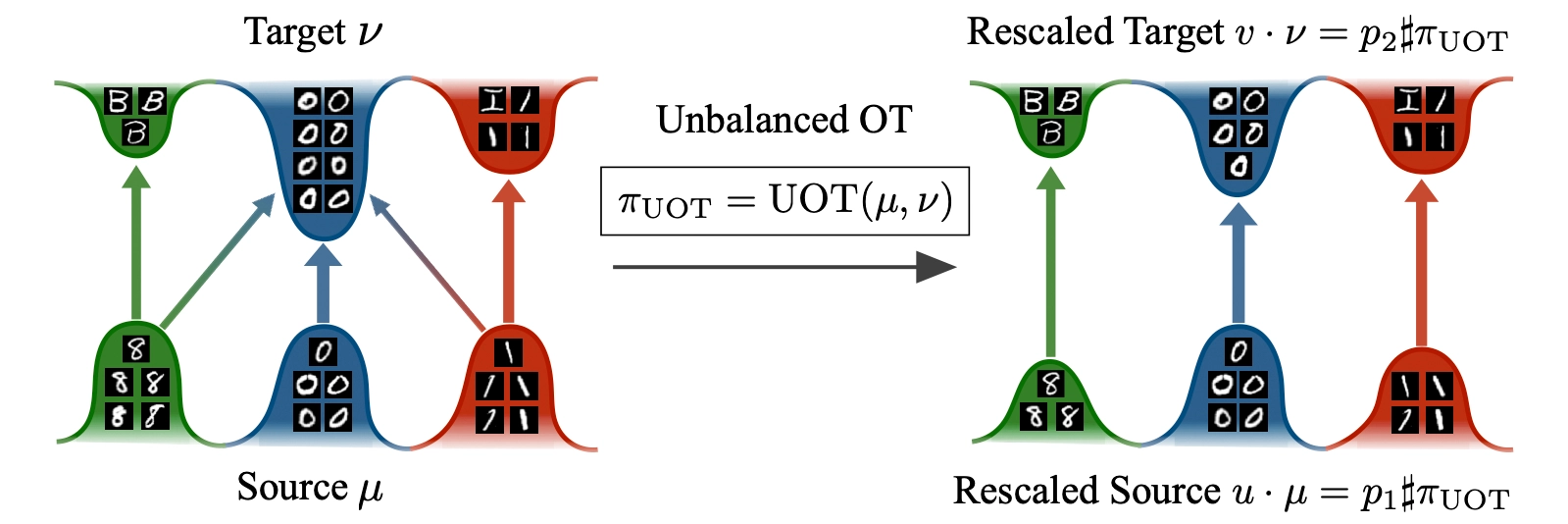
The paper improves Optimal Transport (OT), a method for efficiently transforming one set of data into another. The new UOT-FM approach helps in areas like predicting biological changes and improving image processing by making the transformation more flexible and accurate. This makes OT more useful for real-world applications.
Unbalancedness in Neural Monge Maps Improves Unpaired Domain Translation.
ICLR 2024 - 12th International Conference on Learning Representations. Vienna, Austria, May 07-11, 2024. URL
[4]


The work explores the ethical challenges in the algorithmization of concepts like fairness and diversity in AI. The authors advocate for caution when algorithmically implementing ethical principles and emphasize the importance of human oversight to ensure these systems do not mislead or oversimplify complex ethical dilemmas.
Is diverse and inclusive AI trapped in the gap between reality and algorithmizability?
NLDL 2024 - Northern Lights Deep Learning Conference. Tromsø, Norway, Jan 09-11, 2024. URL
[3]

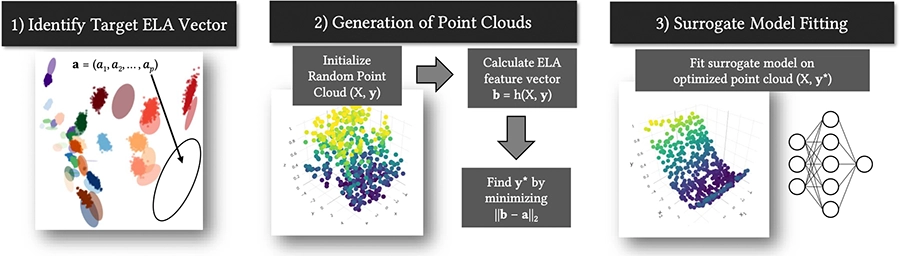
The work introduces a way to create new test functions for optimization problems, where specific characteristics of the problem landscape can be chosen in advance. By adjusting random data and training a simple neural network, the method can recreate known test functions and also generate new ones with properties not seen before.
Neural Networks as Black-Box Benchmark Functions Optimized for Exploratory Landscape Features.
FOGA 2023 - 17th ACM/SIGEVO Conference on Foundations of Genetic Algorithms. Potsdam, Germany, Aug 30-Sep 01, 2023. DOI
[2]


The paper presents the mlr3fairness package which builds upon the ML framework mlr3. The extension contains fairness metrics, fairness visualizations, and model-agnostic pre- and post-processing operators that aim to reduce biases in ML models.
Fairness Audits and Debiasing Using mlr3fairness.
The R Journal 15.1. Aug. 2023. DOI
[1]

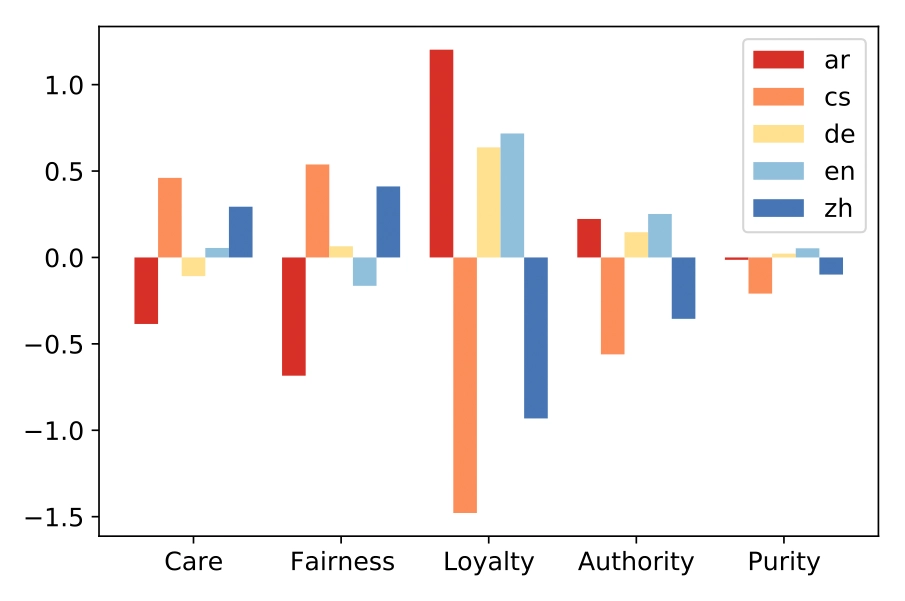
The paper investigates whether pre-trained multilingual language models (PMLMs) impose English moral norms on other languages or show random, potentially harmful biases. Experiments in five languages reveal that the models do encode different moral biases, but these do not consistently reflect real cultural differences. This could cause problems when using such models across languages.
Speaking Multiple Languages Affects the Moral Bias of Language Models.
Findings @ACL 2023 - Findings of the 61th Annual Meeting of the Association for Computational Linguistics. Toronto, Canada, Jul 09-14, 2023. DOI