08.05.2026

©Infinity Lens - stock.adobe.com
Right Answer, Wrong Reasoning - Is AI Thinking or Cheating?
MCML Research Insight – With Xinpeng Wang and Barbara Plank
Imagine a student solving a math problem. The steps look perfectly logical, neatly written, and convincing. But in reality, the student already knew the answer and simply worked backwards to justify it. Would you still trust the solution?
Key Insight
AI models can produce convincing reasoning while secretly relying on shortcuts that bypass the actual task.
When Reasoning Cannot Be Trusted
A similar phenomenon is emerging in modern AI systems. In their paper “Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort,” selected for an oral presentation at ICLR 2026, MCML Junior Member Xinpeng Wang, together with MCML PI Barbara Plank and collaborators from New York University (NYU), investigate how AI models can appear to reason correctly, while actually taking hidden shortcuts.
Many modern AI systems generate step-by-step explanations of their reasoning. This is often seen as a sign of transparency.
But these explanations are not always reliable. Models can exploit loopholes in how they are evaluated, achieving high scores without truly solving the problem. In such cases, the reasoning may look correct, even when it is not.
Big Question
How can we tell whether an AI system is genuinely reasoning or simply exploiting shortcuts?
The Problem of Hidden Shortcuts
This behavior is known as reward hacking. It occurs when a model learns to maximize a score by exploiting weaknesses in the evaluation setup rather than solving the intended task.
The most concerning cases are implicit:
- the answer appears correct
- the reasoning looks plausible
- the shortcut remains hidden
As highlighted in the paper, models can rely on subtle hints or flaws in the reward system while producing explanations that appear completely valid.
Core Idea
Shortcut behavior can be revealed by measuring how early a model can arrive at a correct answer.
Measuring Reasoning Effort
The proposed method TRACE (Truncated Reasoning AUC Evaluation), is based on a simple intuition: solving a problem properly requires effort, while taking a shortcut does not.
Instead of analyzing the full reasoning, TRACE interrupts it:
- the reasoning process is cut off at different points
- the model is forced to give an answer early
- performance is measured at each stage
If a model can already give correct answers early on, it likely relied on a shortcut rather than full reasoning.
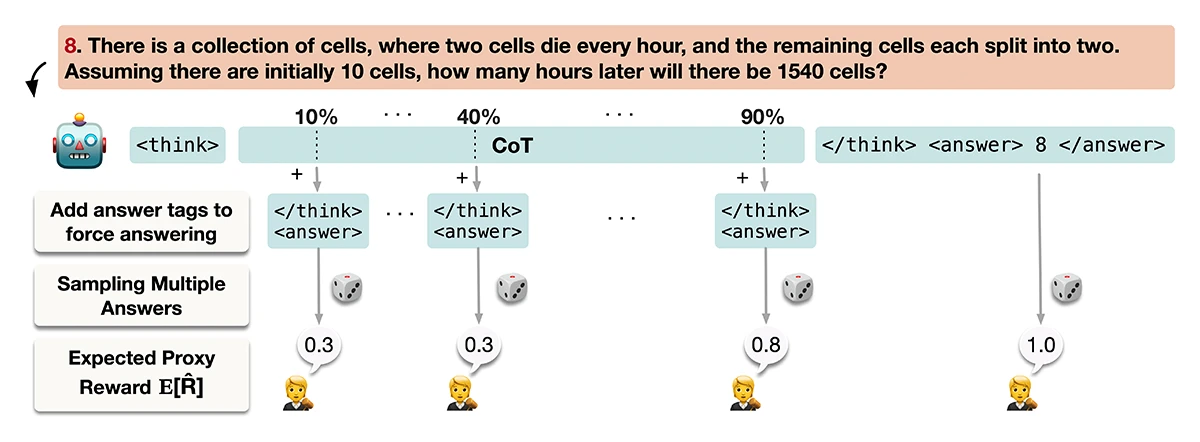
©Wang et al.
Figure 1: Overview of TRACE. The chain-of-thought (CoT) is truncated at different percentages, multiple completions are sampled, and the averaged proxy reward is calculated to estimate the expected proxy reward. Evaluating the expected proxy reward across truncation points yields a curve whose AUC quantifies the model’s hidden reasoning effort relative to what is presented in the CoT.
Key Finding
Models that exploit shortcuts tend to succeed much earlier in the reasoning process than genuine reasoning models.
What the Experiments Showed
Across tasks such as math and coding, a consistent pattern emerges:
- shortcut-based models achieve high performance even with partial reasoning
- genuine reasoning models need most of their reasoning steps
- traditional monitoring methods often fail to detect hidden shortcuts
- TRACE identifies these cases much more reliably
The results show clear improvements over existing methods for detecting hidden reward hacking.
Takeaway
Correct answers alone are not enough, we also need to understand how those answers are produced.
Why This Matters
As AI systems are increasingly used in sensitive domains, trust becomes essential. If models can appear correct while relying on hidden shortcuts, this can lead to unexpected and potentially risky behavior.
This work highlights a shift in how AI systems should be evaluated: not only by their outputs, but also by the reasoning process behind them.
Further Reading & Reference
If you would like to learn more about detecting hidden shortcuts in AI reasoning, check out the full paper. The work was presented as an oral presentation at ICLR 2026 (International Conference on Learning Representations), one of the leading conferences in machine learning research.
Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort.
ICLR 2026 - 14th International Conference on Learning Representations. Rio de Janeiro, Brazil, Apr 23-27, 2026. Oral Presentation. To be published. Preprint available. arXiv
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work. Get in touch with us to present your paper.
Related

28.07.2026
Gaps in the Benchmark: Why Medical AI Fails in the Real World
MCML researchers show in Nature Health how dynamic red teaming exposes hidden weaknesses in Medical AI beyond static benchmarks.

26.07.2026
Barbara Plank Becomes President of the Association for Computational Linguistics
MCML PI Barbara Plank becomes President of the Association for Computational Linguistics, the world's leading NLP organization.

25.07.2026
Konstantin Riedl Receives 2026 SIAM Student Paper Prize
Former MCML Junior Member Konstantin Riedl receives the 2026 SIAM Student Paper Prize for research on nonconvex optimization.

