16.04.2026

©AI-generated
Do Language Models Reason Like Humans?
MCML Research Insight – With Philipp Mondorf and Barbara Plank
Imagine reading the sentence: “If it rains, the streets will be wet.” Most people would consider it perfectly reasonable. Now consider a different statement: “If the moon is made of cheese, the streets will be wet.” Even if the outcome might sometimes happen, the connection suddenly feels strange. Humans constantly evaluate such “if–then” statements, using both probability and meaning to judge whether they make sense.
Key Insight
LLMs consider both probability and meaning when judging “if–then” statements, but their reasoning does not always align with human judgments.
In their paper “If Probable, Then Acceptable? Understanding Conditional Acceptability Judgments in Large Language Models,” MCML Junior Member Philipp Mondorf and MCML PI Barbara Plank, together with collaborator Jasmin Orth, investigate how large language models (LLMs) evaluate the plausibility of conditional statements, and whether their judgments resemble those of humans.
Key Question
Do language models judge the acceptability of “if–then” statements using the same signals as humans?
Key Question
Do language models judge the acceptability of “if–then” statements using the same signals as humans?
The Idea
Conditional statements of the form “If A, then B” play a central role in communication and reasoning. People use them to make predictions, evaluate arguments, and reason about hypothetical situations. When humans judge whether such statements are acceptable, two factors are particularly important: the conditional probability of the outcome given the premise, and the semantic relevance between the two parts of the statement—whether the premise meaningfully supports the conclusion.
As LLMs become widely used in applications that generate explanations, arguments, or recommendations, it becomes important to understand how they interpret such logical structures. Do they evaluate conditional statements using the same cues that humans rely on?
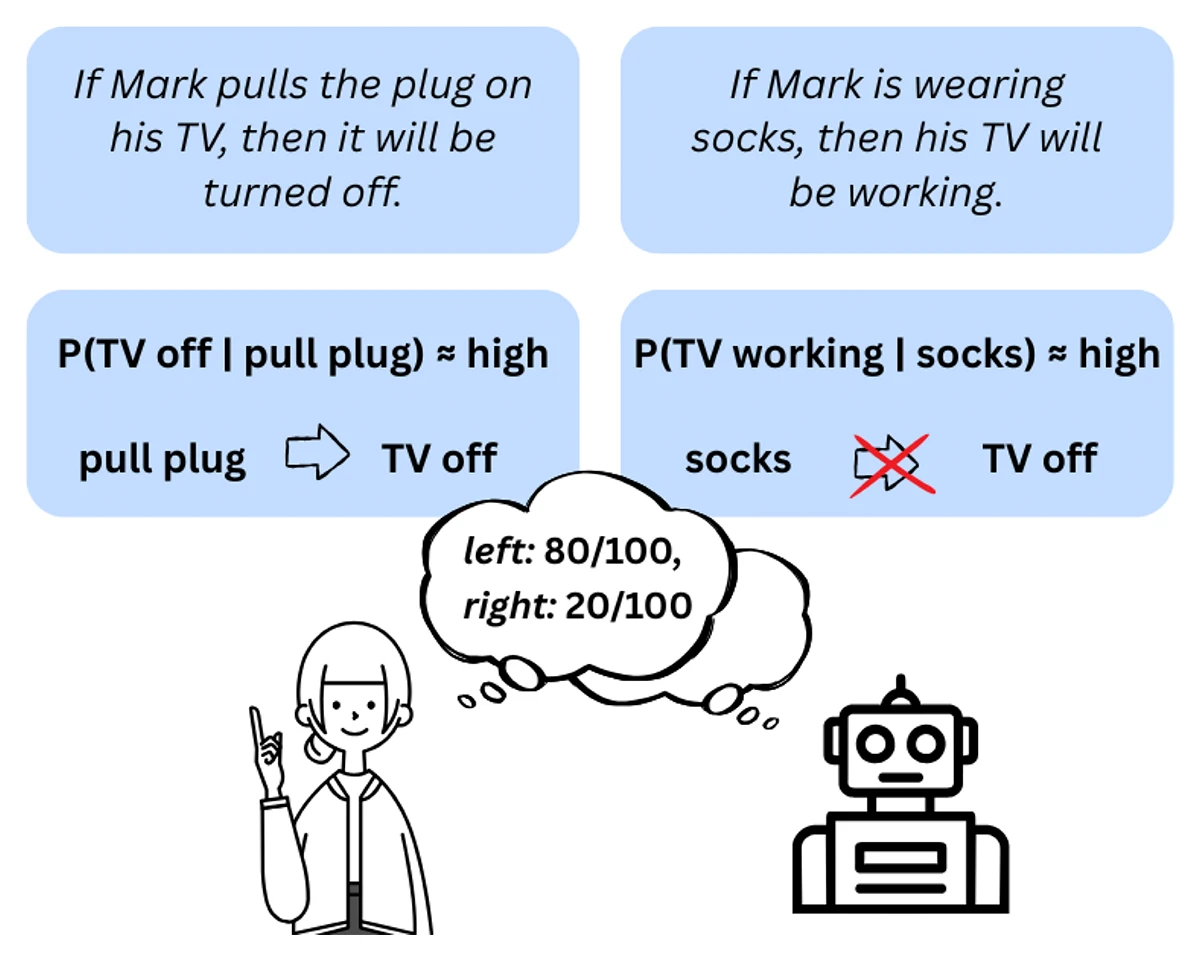
©Orth et al.
Figure 1: Illustration of two conditionals with equally high conditional probabilities but differing evidential relevance. While both are probable, only the left one encodes a plausible causal or evidential link between antecedent and consequent, appearing more acceptable.
Core Idea
Compare LLM judgments with human reasoning by analyzing how probability and semantic relevance influence the perceived acceptability of conditional statements.
Research Approach
To explore this question, the researchers conducted a systematic study of how different large language models evaluate conditional statements. They tested multiple model families, model sizes, and prompting strategies, presenting models with a range of conditional statements and asking them to judge how acceptable they were.
The analysis focused on two key factors known to influence human reasoning: conditional probability and semantic relevance. Using statistical techniques such as linear mixed-effects models and ANOVA, the researchers examined how strongly these factors influenced the models’ judgments. The results were then compared with human judgment data from earlier cognitive studies.
Key Finding
Language models incorporate probabilistic and semantic cues when evaluating conditionals, but their reasoning patterns still differ from human judgments.
Key Finding
Language models incorporate probabilistic and semantic cues when evaluating conditionals, but their reasoning patterns still differ from human judgments.
Key Findings
The study reveals several interesting patterns in how language models evaluate conditional statements:
- Models respond to probability. Statements where the conclusion is likely given the premise tend to be rated as more acceptable.
- Semantic relevance matters as well. When the premise meaningfully supports the conclusion, models judge the statement as more plausible.
- Alignment with humans is incomplete. While LLMs rely on similar cues, they apply them less consistently than humans do.
- Larger models are not necessarily more human-like. Increasing model size does not automatically lead to judgments that better match human reasoning.
Takeaway
Studying how AI evaluates “if–then” statements helps reveal both the strengths and limitations of machine reasoning.
Why This Matters
As language models are increasingly used to assist with reasoning, explanation, and decision support, understanding how they interpret logical statements becomes crucial. If AI systems evaluate conditional statements differently from humans, this could influence how they generate arguments, explain conclusions, or guide decision-making.
Research like this helps uncover where AI reasoning aligns with human cognition, and where important differences remain. By better understanding these differences, researchers can develop models that reason more transparently and communicate more effectively with human users.
Further Reading & Reference
If you would like to learn more about how language models judge the acceptability of conditional statements and how these judgments compare with human reasoning, you can explore the full paper. The work will be presented at EACL 2026 (Conference of the European Chapter of the Association for Computational Linguistics), one of the leading international conferences in natural language processing research.
If Probable, Then Acceptable? Understanding Conditional Acceptability Judgments in Large Language Models.
EACL 2026 - 19th Conference of the European Chapter of the Association for Computational Linguistics. Rabat, Morocco, Mar 24-29, 2026. DOI
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

31.07.2026
Benedikt Wiestler: We Want to Build a Time Machine
MCML PI Benedikt Wiestler explains how AI models help to develop specific strategies in clinical therapy for brain tumor patients.

28.07.2026
Gaps in the Benchmark: Why Medical AI Fails in the Real World
MCML researchers show in Nature Health how dynamic red teaming exposes hidden weaknesses in Medical AI beyond static benchmarks.

26.07.2026
Barbara Plank Becomes President of the Association for Computational Linguistics
MCML PI Barbara Plank becomes President of the Association for Computational Linguistics, the world's leading NLP organization.

