19.03.2026

Teaching Models to Say ‘I’m Not Sure’
MCML Research Insight – With Hannah Laus, Felix Krahmer and Holger Rauhut
Machine learning models are good at giving answers, predicting patterns, and classifying objects but they are much worse at saying when they are unsure. But what if the model could admit when it was guessing and quantify the uncertainty?
This question is addressed by MCML Junior Member Hannah Laus, together with MCML PIs Felix Krahmer and Holger Rauhut, and collaborators Frederik Hoppe and former MCML Member Claudio Mayrink Verdun in their NeurIPS 2024 (Spotlight) paper “Non-Asymptotic Uncertainty Quantification in High-Dimensional Learning.” Rather than introducing yet another uncertainty heuristic, the paper revisits the theoretical foundations of uncertainty quantification with a clear focus on making them usable in practice.
Uncertainty Without Infinite Data
When a model makes a prediction, how much should we trust it? One of the most common ways to answer this question is through confidence intervals: ranges around a prediction that tells us where the true value is likely to fall. For example, instead of saying “the model predicts 2.3,” we say “the model predicts 2.3, but it could reasonably be anywhere between 2.0 and 2.6.” A wider interval shows lower confidence while a narrower one indicates the model is more sure. The key question, then, is: how wide should these intervals be?
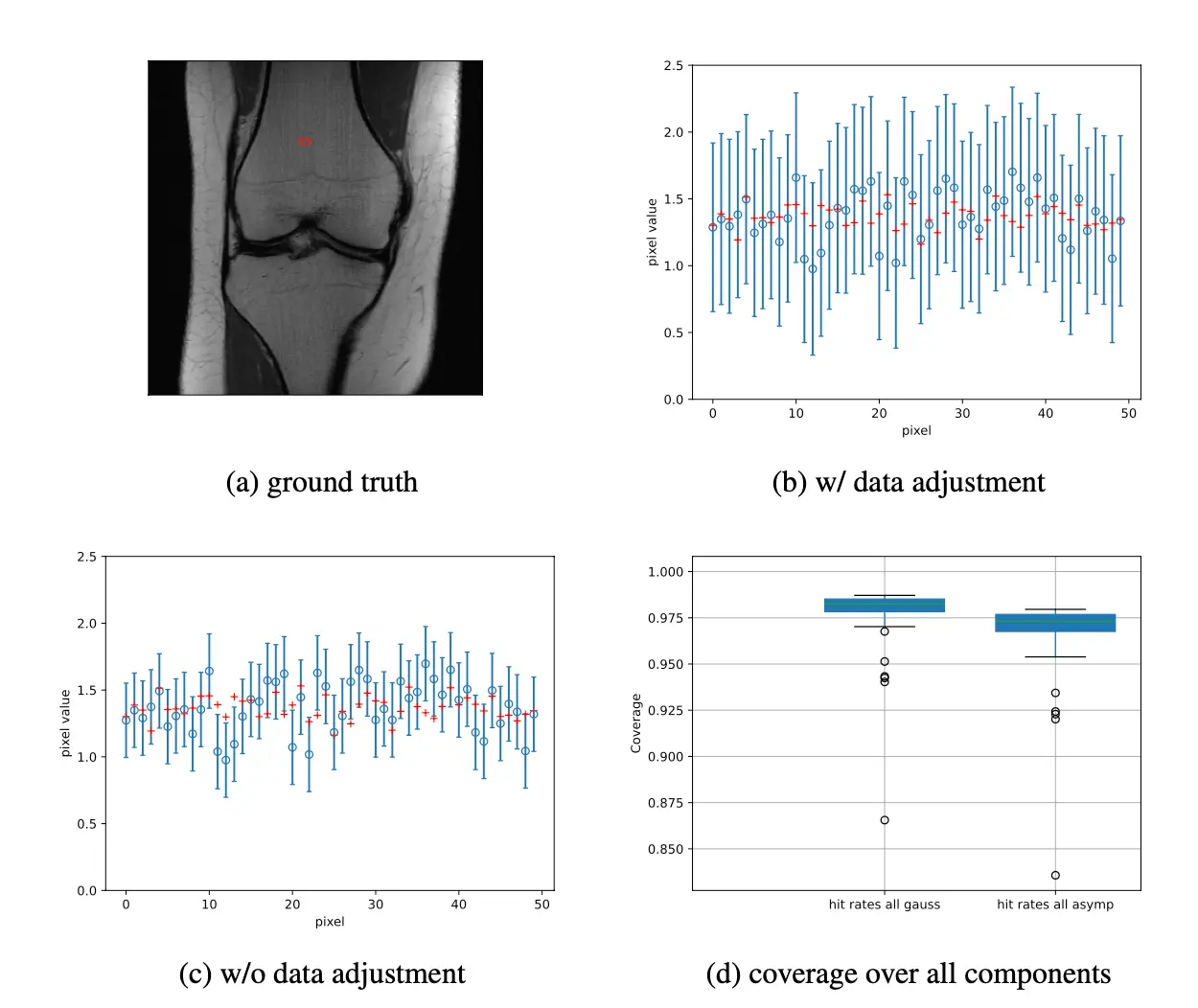
Classical approaches rely on asymptotic theory. In simple terms, they assume that if we had enough data and high enough dimensions, certain sources of error would shrink to zero and could safely be ignored. In practice, however, data is finite and dimensions are large but not infinite. The supposedly negligible error terms often remain significant, leading to confidence intervals that are too narrow and overly optimistic — a serious issue in safety-critical applications such as medical imaging.
Where Classical Theory Breaks Down
Prediction error typically consists of two parts:
- A Gaussian noise component from measurements.
- A remainder term from estimation inaccuracies.
Traditional theory ignores the remainder because it vanishes asymptotically. In realistic settings, it does not. Ignoring it results in undercoverage — confidence intervals that fail to contain the true value as often as claimed.
«We believe that our method is applicable to a wide variety of deep learning architectures, including vision transformers in MRI.»
Laus et al.
MCML Junior Member
A Data-Driven Correction
The authors propose estimating the remainder directly from held-out training data, where the ground truth is known. By measuring its empirical mean and variance, they adjust the confidence intervals accordingly.
The result: intervals that are wider but mathematically guaranteed to achieve the desired coverage — not heuristically, but rigorously.
Beyond Classical Regression: Neural Networks Too
Importantly, the method treats the estimator as a black box. It therefore applies not only to classical sparse regression but also to modern model-based deep learning methods such as unrolled neural networks used in inverse problems.
Experiments in sparse regression and MRI knee reconstruction show that standard intervals systematically underperform, while the corrected intervals meet or exceed the target coverage.
Why It Matters
This work bridges theory and practice by enabling reliable uncertainty quantification without unrealistic assumptions. While motivated by MRI reconstruction, given the collaboration between TUM and RWTH with GE Healthcare, the framework applies broadly to inverse problems — from seismic imaging to astronomy to materials science.
Accurate predictions are not enough. Reliable machine learning systems must also know when they might be wrong. Sometimes, the most important prediction a model can make is: “I’m not sure.”
Further Reading & Reference
If you would like to learn more about quantifying uncertainty and try it yourself, you can find additional details at the links below:
Non-Asymptotic Uncertainty Quantification in High-Dimensional Learning.
NeurIPS 2024 - 38th Conference on Neural Information Processing Systems. Vancouver, Canada, Dec 10-15, 2024. URL
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

02.04.2026
How AI Avatars Shape Perceived Fairness
Accepted at CHI 2026, this study shows how the race and gender of AI interview avatars shape perceptions of fairness and bias in automated hiring.

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

