24.07.2025

SceneDINO: How AI Learns to See and Understand Images in 3D–Without Human Labels
MCML Research Insight - With Christoph Reich, Felix Wimbauer, and Daniel Cremers
Imagine looking at a single image and trying to understand the entire 3D scenery–not just what’s visible, but also what’s occluded. Humans do this effortlessly: when we see a photo of a tree, we intuitively grasp its 3D structure and semantic meaning. We learn this ability through interaction and movement in the 3D world, without explicit supervision. Inspired by this natural capability, our Junior Members–Christoph Reich and Felix Wimbauer–together with MCML Director Daniel Cremers and collaborators Aleksandar Jevtić, Oliver Hahn, Christian Rupprecht, and Stefan Roth from TUM, TU Darmstadt, and the University of Oxford, developed a novel approach: 🦖 Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion. SceneDINO can infer both 3D geometry and semantics from a single image–entirely without labeled training data.
©Jevtić et al.
SceneDINO overview. Given a single input image, SceneDINO estimates 3D scene geometry, expressive features, and unsupervised semantics in a feed-forward manner, without using any human annotations.
«We present SceneDINO, the first approach for unsupervised semantic scene completion.»
Christoph Reich et al.
MCML Junior Members
Why Unsupervised Geometric and Semantic Understanding in 3D Matters
Autonomous agents–from self-driving cars to mobile robots–navigate a world that is fundamentally three-dimensional. To operate safely and intelligently, they must understand both the geometry and semantics of their surroundings in 3D. While modern sensors like LiDAR can provide accurate geometric measurements, these sensors are expensive, offer only sparse information, and are not applicable in some domains, such as medical endoscopy. On top of that, obtaining semantic annotations in 3D is immensely time and resource-intensive, preventing the collection of large amounts of annotated training examples.
Approaching the understanding of geometry and semantics in 3D purely from images without human annotations offers a compelling alternative to overcome the limitations associated with expensive sensors and semantic annotations. SceneDINO builds the first approach to estimate both 3D geometry and semantics from a single image, without requiring human annotations for training.
«Trained using 2D self-supervised features and multi-view self-supervision SceneDINO predicts 3D geometry and 3D features from a single image.»
Christoph Reich et al.
MCML Junior Members
How to Understand the 3D World Without Human Supervision
Humans naturally perceive a scene from multiple viewpoints by simply moving through the world. SceneDINO draws inspiration from this process by learning from multi-view images during training. The training consists of two stages: First, SceneDINO uses multi-view self-supervision to learn a 3D feature field that captures both the 3D geometry of the scene and semantically meaningful features, all without human labels. In the second stage, the rich feature field is distilled and clustered to produce unsupervised semantic predictions in 3D.
©Jevtić et al.
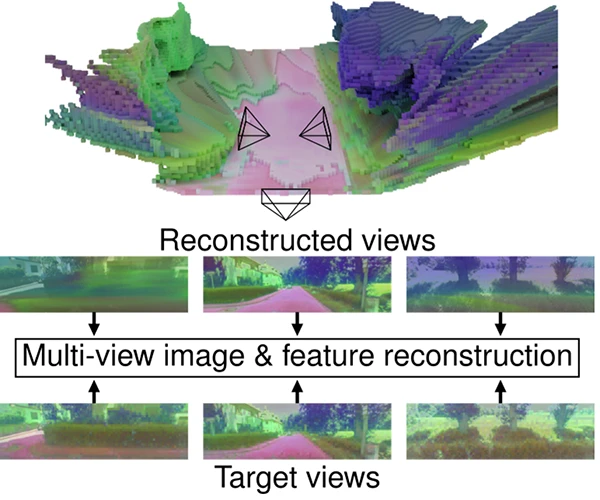
Multi-view self-supervision
Multi-View Self-Supervision
Given a single input image, SceneDINO estimates a 3D feature field. Through volumetric rendering, synthesized images and 2D features from novel viewpoints can be estimated. For self-supervision, SceneDINO’s training leverages additional images captured from different viewpoints and learns to reconstruct them. By also reconstructing 2D multi-view features from a self-supervised image model, SceneDINO learns an expressive and multi-view consistent feature field in 3D.
©Jevtić et al.
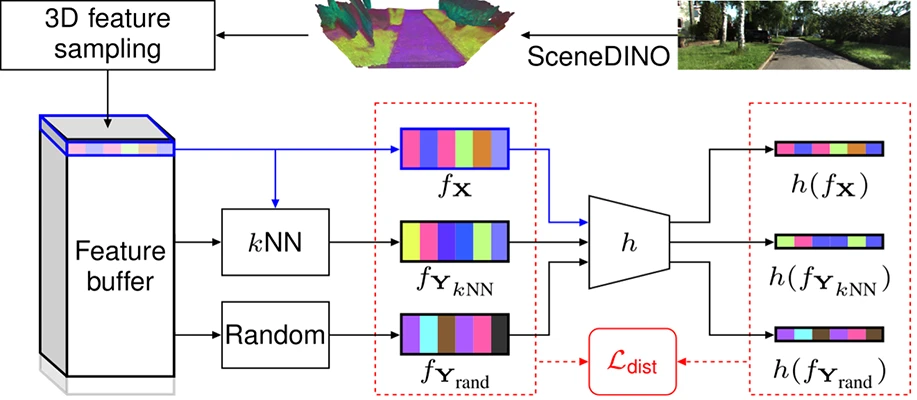
Distillation and clustering
Distillation and Clustering
SceneDINO’s features are expressive and capture semantic concepts. To enhance these semantic concepts, SceneDINO’s features are distilled in 3D. By amplifying similarities and dissimilarities between 3D features using our pr geometry, we obtain semantically enhanced features. Clustering these features results in semantic prediction, grouping semantically coherent regions in a fully unsupervised way.
«Multi-view feature consistency, linear probing, and domain generalization results highlight the potential of SceneDINO as a strong foundation for 3D scene-understanding.»
Christoph Reich et al.
MCML Junior Members
Highlights of SceneDINO
SceneDINO can perform fully unsupervised semantic scene completion–the computer vision task of estimating dense 3D geometry and semantics.
- Unsupervised Semantic Scene Completion: SceneDINO is the first approach to perform semantic scene completion (SSC)–the computer vision task of estimating dense 3D geometry and semantics–without requiring any human labels
- Unsupervised SSC Accuracy: SceneDINO achieves state-of-the-art accuracy in SSC compared to a competitive baseline (also proposed in the paper)
- A Strong Foundation: Beyond unsupervised SSC, SceneDINO offers general, expressive, and multi-view consistent 3D features, providing a strong foundation for approaching 3D scene-understanding using limited human annotations
«Our novel 3D distillation approach yields state-of-the-art results in unsupervised SSC.»
Christoph Reich et al.
MCML Junior Members
SceneDINO in Action
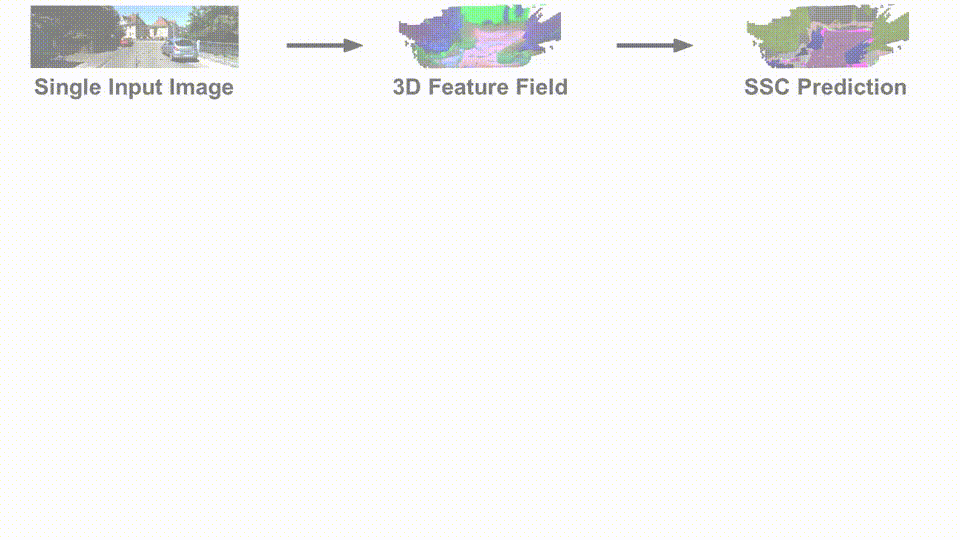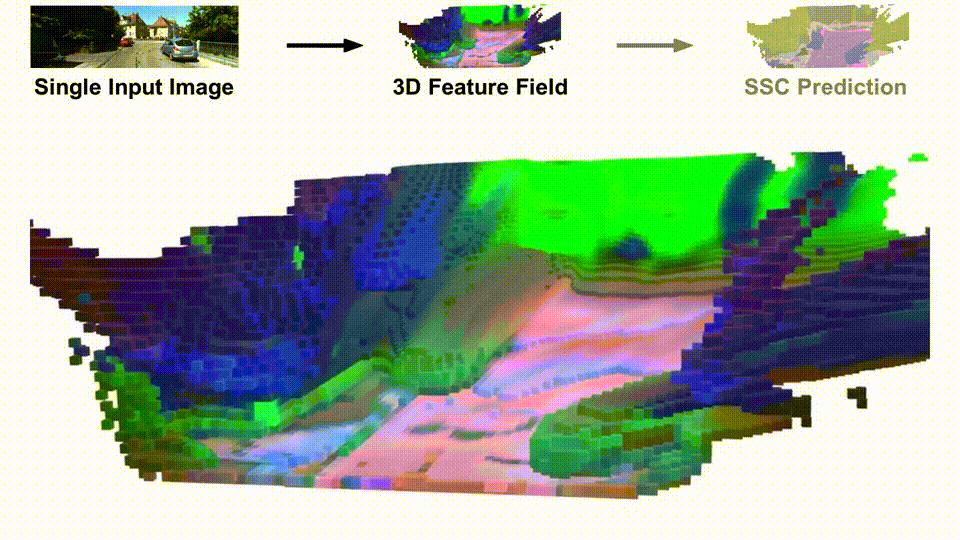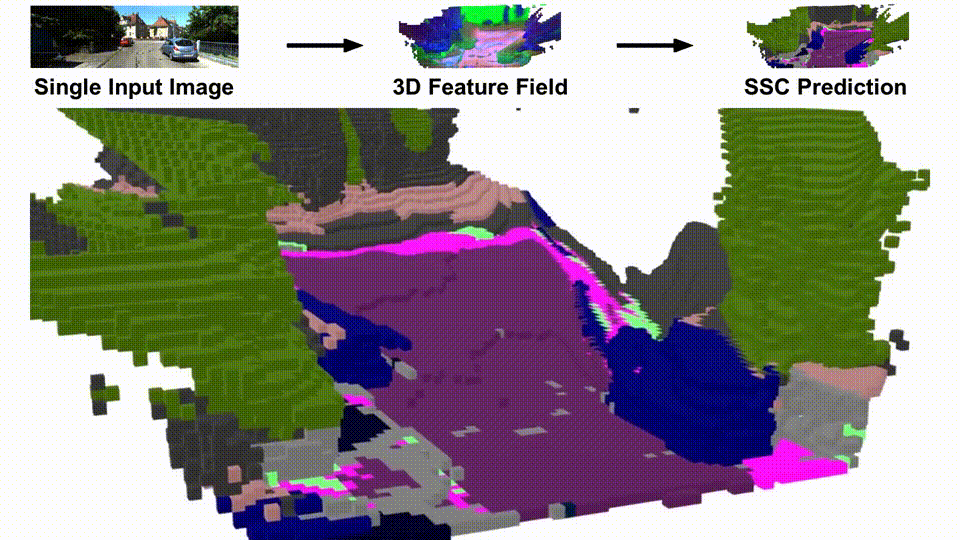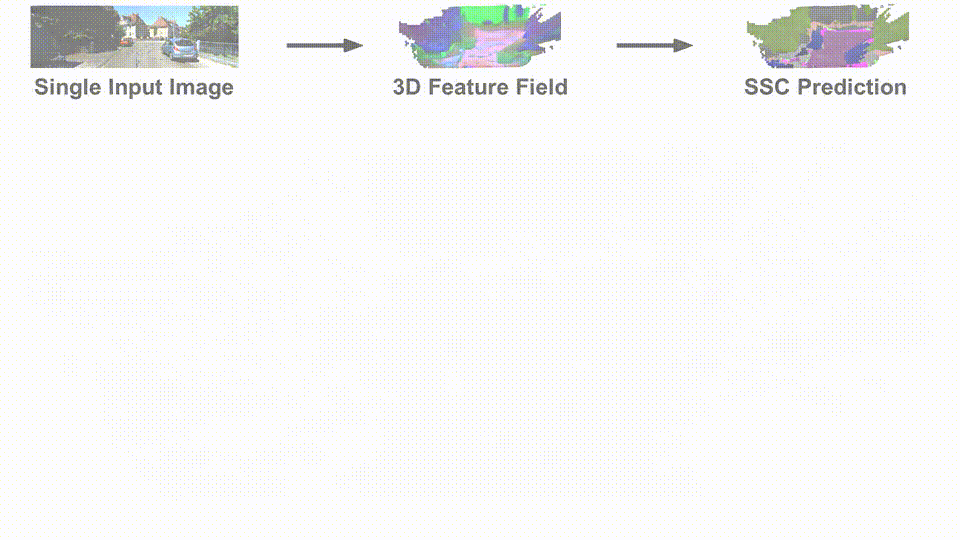
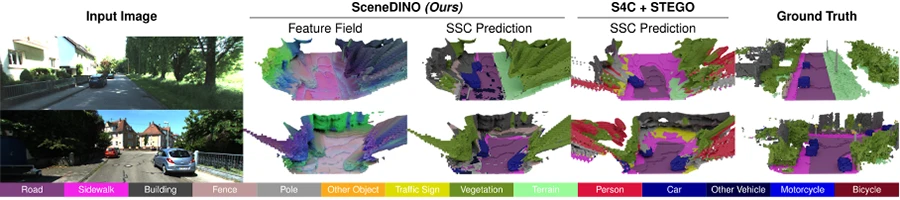
Given a single input image, SceneDINO achieves impressive 3D reconstructions and segmentation results, without using any human annotations. Compared to the proposed unsupervised baseline (S4C + STEGO), SceneDINO better captures the semantic structure of the scene. Especially for distant structures, SceneDINOs’ semantic predictions are significantly improved. SceneDINO’s high-dimensional feature field, visualized using a dimensionality reduction approach, includes highly semantically rich features.
©Jevtić et al.
SceneDINO in action. Given a single input image of a complex scene, SceneDINO estimates an expressive feature field. From this feature field, SceneDINO can accurately segment the scene in 3D.
Further Reading & Reference
While this blog post highlights the core ideas of SceneDINO, the respective ICCV 2025 paper takes a deep look at the entire methodology, including how training, distillation, and clustering are performed.
If you’re interested in how SceneDINO compares to other methods–or want to explore the technical innovations behind its strong performance–check out the full paper accepted to ICCV 2025, one of the most prestigious conferences in the field of computer vision.
Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion.
ICCV 2025 - IEEE/CVF International Conference on Computer Vision. Honolulu, Hawai’i, Oct 19-23, 2025. To be published. Preprint available. URL GitHub
Curious to Test SceneDINO on Your Own Images?
The authors provide an online demo, and the code is open-source–check out the Hugging Face demo and the GitHub repository.
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

