10.04.2025

Text2Loc: A Smarter Way to Navigate With Words
MCML Research Insight - With Yan Xia, Zifeng Ding and Daniel Cremers
Imagine standing in an unfamiliar part of a city, no GPS in sight. All you can say is, “I’m west of a green building, near a black garage.” That might be vague to a machine, but Text2Loc understands you perfectly. With this powerful new system, AI can find your exact location in a 3D map - just from how you describe the world around you.
«3D localization using natural language descriptions in a city-scale map is crucial for enabling autonomous agents to cooperate with humans to plan their trajectories in applications such as goods delivery or vehicle pickup.»
Yan Xia et al.
MCML Junior Members
The Challenge of 3D Localization
Navigating a city without GPS and relying only on descriptions like “I’m near a black pole, west of a gray-green road” is easy for humans. However, AI struggles with this task, especially in autonomous robots and self-driving cars that rely on 3D point clouds - detailed digital maps of the environment made up of millions of tiny points. These points are captured using sensors like LiDAR, which scan surroundings to create a 3D representation of objects, roads, and buildings.
Traditional methods try to match each word in a user’s description (like “black pole” or “gray road”) to specific objects in the environment, called text-instance matching. That’s slow, unreliable, and not very human-like. Worse, when the description is a bit vague - or there are multiple similar objects - these systems fail to pinpoint the exact spot, which is often referred to as the “last mile problem”.
The recent paper “Text2Loc: 3D Point Cloud Localization from Natural Language”, developed by our MCML Junior Members Yan Xia, Zifeng Ding, our Director Daniel Cremers, and collaborators Letian Shi and Joao F. Henriques, takes a different approach by first retrieving relevant submaps and then refining the location using a hierarchical approach. This method speeds up localization and improves accuracy, making it a major step forward for text-based navigation and tackling the “last mile problem”.
How Text2Loc Works

©Yan Xia et al.
The proposed Text2Loc architecture.
The proposed Text2Loc architecture consists of two tandem modules:
- Global place recognition: Given a text-based position description, Text2Loc first identifies a set of coarse candidate locations, “submaps,” potentially containing the target position. This is achieved by retrieving the top-k nearest submaps from a previously constructed database of submaps using the novel text-to-submap retrieval model.
- Fine localization: Text2Loc then refines the center coordinates of the retrieved submaps via the designed matching-free position estimation module, which adjusts the target location to increase accuracy.
«Extensive experiments demonstrate that Text2Loc improves the localization performance over the state-of-the-art by a large margin.»
Yan Xia et al.
MCML Junior Members
Text Descriptions as Input
Instead of relying on precise coordinates, Text2Loc understands natural language descriptions such as:
- “The pose is on top of a gray road.”
- “The pose is west of a black vegetation.”
These descriptions allow for intuitive, human-like localization, making it possible for systems to process spatial information the way people naturally describe their surroundings.
Global Place Recognition (Text-to-Submap Retrieval)
Rather than searching for a single matching object, Text2Loc retrieves the most relevant submaps from a large 3D environment. This reduces the complexity of the search while increasing accuracy.
«We are the first to completely remove the usage of text-instance matcher in the final localization stage.»
Yan Xia et al.
MCML Junior Members
Fine Localization (Instances in Retrieved Submaps)
After retrieving relevant submaps, Text2Loc performs fine localization by estimating the precise position within each submap. Unlike previous methods, it does not use a text-instance matching module to explicitly link words in the description to objects in the environment.
Instead, Text2Loc applies a neural network that operates directly on the spatial and semantic features of the submap and the input text. The model jointly encodes these features using a hierarchical architecture that captures both coarse and fine-grained spatial relationships.
This approach allows the system to predict a location without requiring object-level matching, which simplifies training and reduces inference time. This enables last-mile localization, ensuring that the system can pinpoint a precise location even in dense, real-world environments where GPS might fail.
Why Text2Loc Is a True Innovation
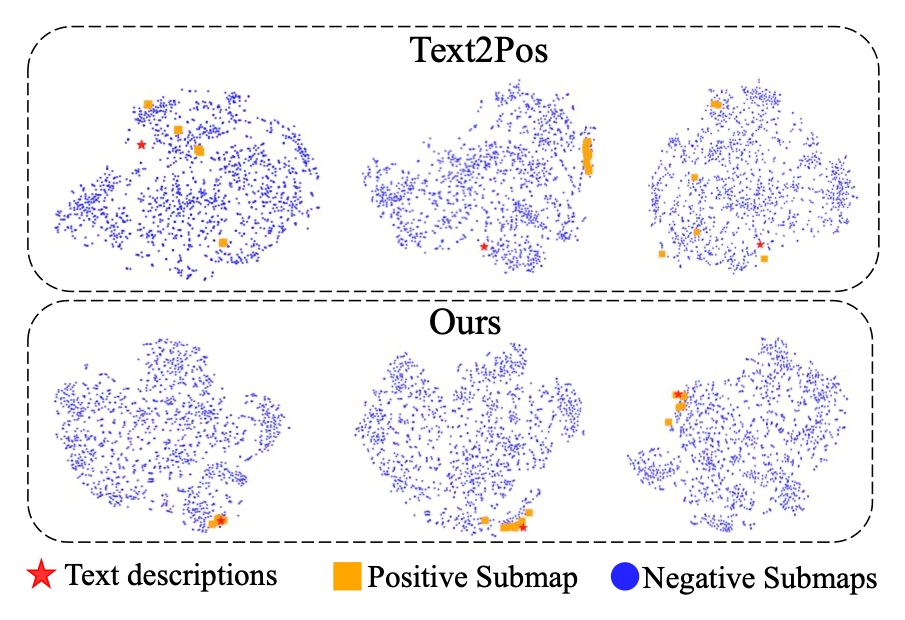
©Yan Xia et al.
T-SNE visualization for global place recognition. It can be seen that Text2Loc (with label "Ours") outperforms Text2Pose, a pioneering work that uses text-instance matching.
Text2Loc introduces a new paradigm in text-based 3D localization. Unlike older approaches that struggle with direct text-object matching, this method simplifies the process while improving precision. Instead of processing every object individually, it retrieves relevant submaps, understands spatial relationships hierarchically, and refines the localization using a novel matching-free position estimation module.
By leveraging natural language and retrieval-based localization, Text2Loc enables AI to navigate the world the way humans do - through words. This innovation makes it incredibly useful for goods delivery and vehicle pickup, where precise, text-driven localization is essential.
Read More
While this article introduces key concepts, the original paper explores detailed insights into global place recognition and fine localization. If you want to understand the full methodology behind Text2Loc, including its advantages over traditional approaches, check out the original paper published at the CVPR 2024, one of the highest-ranked AI/ML conferences.
Text2Loc: 3D Point Cloud Localization from Natural Language.
CVPR 2024 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA, Jun 17-21, 2024. DOI GitHub

©Yan Xia et al.
The authors at CVPR 2024
©Yan Xia et al.
Poster session at CVPR 2024
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

03.07.2026
MCML at ICML 2026
MCML researchers are represented with 82 papers at ICML 2026 (70 Main, and 12 Workshops).
03.07.2026
Christian Kühn Receives Award From the Mathematics and Environment Foundation
The Mathematics and Environment Foundation honors Christian Kühn with the Ernst P. Stephan Award.

02.07.2026
Study Reveals Privacy Risks in Medical AI
Study led by MCML Director Daniel Rückert reveals higher privacy risks in medical AI models.