05.02.2026

Needle in a Haystack: Finding Exact Moments in Long Videos
MCML Research Insight - With With Tanveer Hannan and Thomas Seidl
Long videos are everywhere, with footage of movies, YouTube videos, body-cam recordings, and AR/VR often running for tens of minutes or even hours. Now imagine asking a simple question like “Where are the scissors in this video?”
«Locating specific moments within long videos (20–120 minutes) presents a significant challenge, akin to finding a needle in a haystack.»
Tanveer Hannan
MCML Junior Member
Finding the exact moment in a one-hour video is like searching for a needle in a haystack. While many existing models work well for short clips of a few seconds, they struggle badly when videos become long.
This is the problem addressed in the paper “RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos”. In this work, MCML Junior Member Tanveer Hannan, along with MCML Director Thomas Seidl and collaborators Md Mohaiminul Islam and Gedas Bertasius propose a new model that can efficiently and accurately locate precise moments inside very long videos, all in a single, unified system called RGNet.
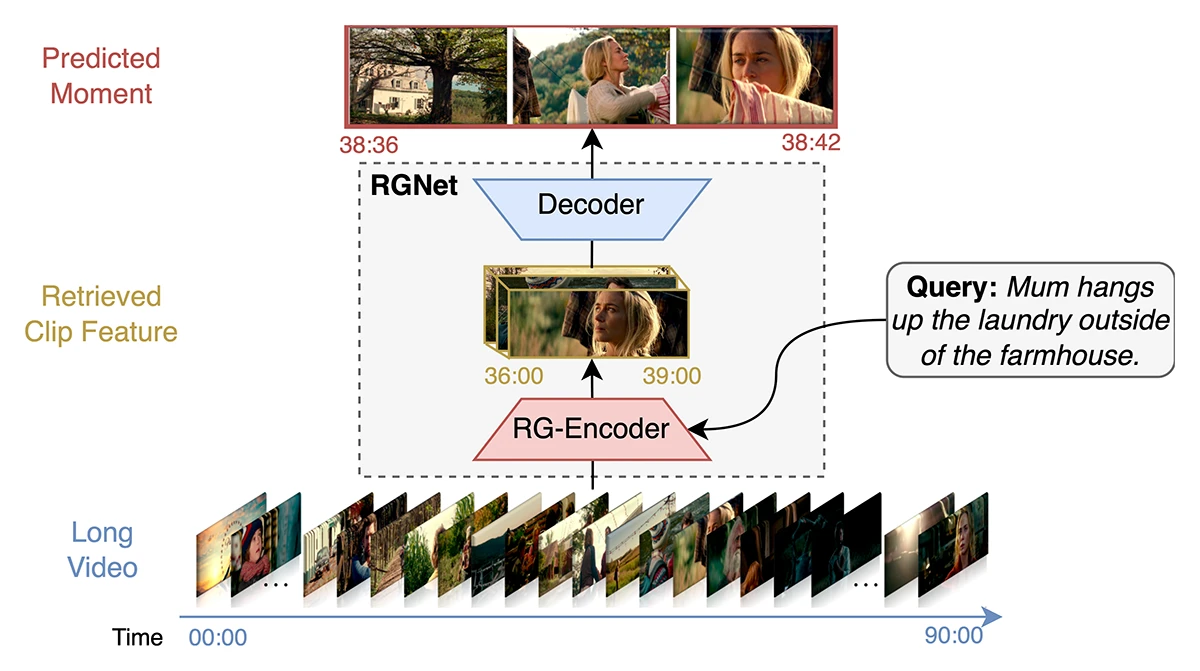
©Hannan et al.
Figure 1: Overview of RGNet. Given a textual query and an hour-long video, RGNet predicts the precise start and end time of the queried event. The RG-Encoder jointly processes video and text features to retrieve the most relevant clip, while the grounding decoder localizes the exact moment within that clip. The encoder operates at multiple levels of granularity, combining clip-level context with frame-level detail in an end-to-end framework.
The Idea Behind the Paper
Most long-video search systems work in two steps. First, they retrieve a short clip that might contain the event described by the text query. Then, they try to precisely locate the start and end of the event within that clip. The main problem with this approach is that if the first step retrieves the wrong clip, the second step cannot recover.
RGNet addresses this issue by combining clip retrieval and moment localization into a single model. Instead of treating them as separate tasks, RGNet learns both at the same time. The model looks at videos at two levels: longer clips for overall context, and individual frames for fine-grained details. By directly optimizing, RGNet learns to focus on the most relevant parts of the video and better capture short events in very long videos.
«The disjoint process limits the retrieval module’s fine-grained event understanding, crucial for specific moment detection.»
Tanveer Hannan
MCML Junior Member
The Intuition Behind RGNet
RGNet splits a long video into overlapping clips and processes them together with the text query using a transformer. Rather than analyzing every frame equally, the model learns to ignore irrelevant content and focus on frames that are likely related to the query. Based on this focused representation, RGNet identifies the most relevant clip and predicts the exact start and end time of the event.
A key advantage of this design is that clip retrieval is trained using the same objective as final localization. This encourages the model to retrieve clips that support precise grounding, rather than clips that are only loosely related to the text.
Results
The authors evaluate RGNet on two challenging benchmarks for long-video understanding: Ego4D-NLQ, and MAD (movie-length videos). Across both datasets, RGNet outperforms previous methods, achieving higher accuracy in both clip retrieval and moment localization. In addition, RGNet is more efficient, as it requires fewer clips to make accurate predictions.
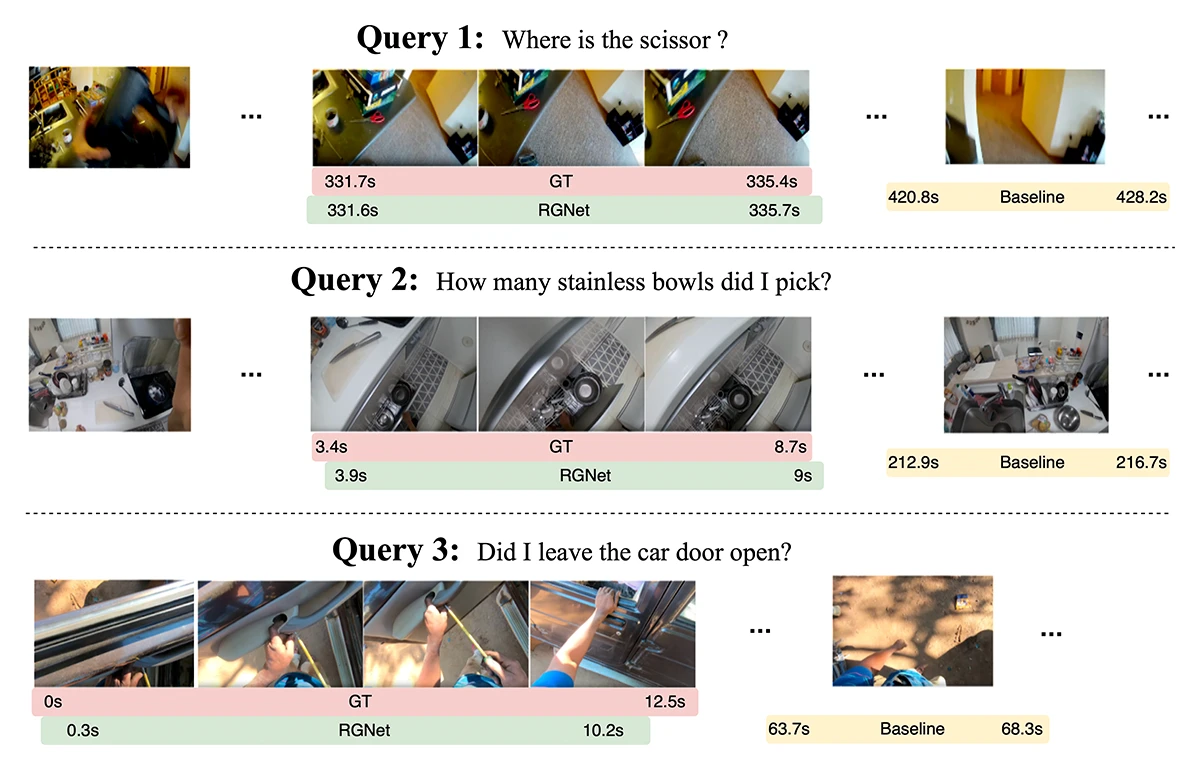
©Hannan et al.
Figure 2: Qualitative results comparing RGNet with a baseline method on long videos. For the first two queries, the baseline retrieves incorrect clips because the scenes look visually similar across the video, making fine-grained event discrimination difficult. In the third query, the baseline retrieves the correct clip but fails to localize the event precisely, detecting it only after the action has already finished.
«Our approach demonstrates state-of-the-art performance on challenging long video grounding datasets, validating its effectiveness.»
Tanveer Hannan
MCML Junior Member
Why This Matters
In real-world videos, important events are often short and easy to miss. Systems that separate clip retrieval from localization are fragile and can fail when the wrong clip is selected. By unifying these steps, RGNet provides a more robust and efficient approach to long-video understanding. This makes it well-suited for applications such as video search, video assistants, and large-scale video analysis.
Challenges and Next Steps
While RGNet shows strong results, challenges remain. Training is still computationally expensive, and the model relies on pre-extracted visual features. Scaling to even longer videos or learning directly from raw video remains an open direction for future work.
Further Reading & Reference
If you’d like to learn more about how RGNet enables precise moment localization in long videos, the full paper and code are available below. The work was presented at ECCV 2024, one of the leading international conferences in computer vision.
RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos.
ECCV 2024 - 18th European Conference on Computer Vision. Milano, Italy, Sep 29-Oct 04, 2024. DOI GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

09.07.2026
MCML Junior Member Bolei Ma Earns Best Paper and SAC Highlight Awards at ACL 2026
Bolei Ma receives a Best Paper Award and an SAC Highlight Award at ACL 2026 for outstanding contributions to NLP research.

08.07.2026
How Autonomous Systems Learn to Understand Their Environment
The team at the startup SE3 Labs has developed a spatial AI technology that uses images, videos, and map data to create realistic 3D models.

08.07.2026
MCML Junior Member Sarah Ball Receives Outstanding Position Paper Award at ICML 2026
MCML Junior Member Sarah Ball and her co-author Phil Hackemann received the Outstanding Position Paper Award at ICML 2026 this week in Seoul.

