15.01.2026

Blind Matching – Aligning Images and Text Without Training or Labels
MCML Research Insight - With Dominik Schnaus, Nikita Araslanov, and Daniel Cremers
Vision-language models have shown that images and text can live in a shared space: a picture of a “cat” often lands close to the word “cat” in the embedding space. But such models learn this correspondence because they have seen millions of image–caption pairs. What if we had no paired data at all? Could we still figure out which images match which words?
This is the question behind the CVPR 2025 paper “It’s a (Blind) Match! Towards Vision-Language Correspondence without Parallel Data”. MCML Junior Members Dominik Schnaus, and Nikita Araslanov, together with MCML Director Daniel Cremers, investigate whether it is possible to align images and text completely unsupervised, with no captions, no labels, no matching pairs. Surprisingly, the answer is: yes, for many cases, we can.
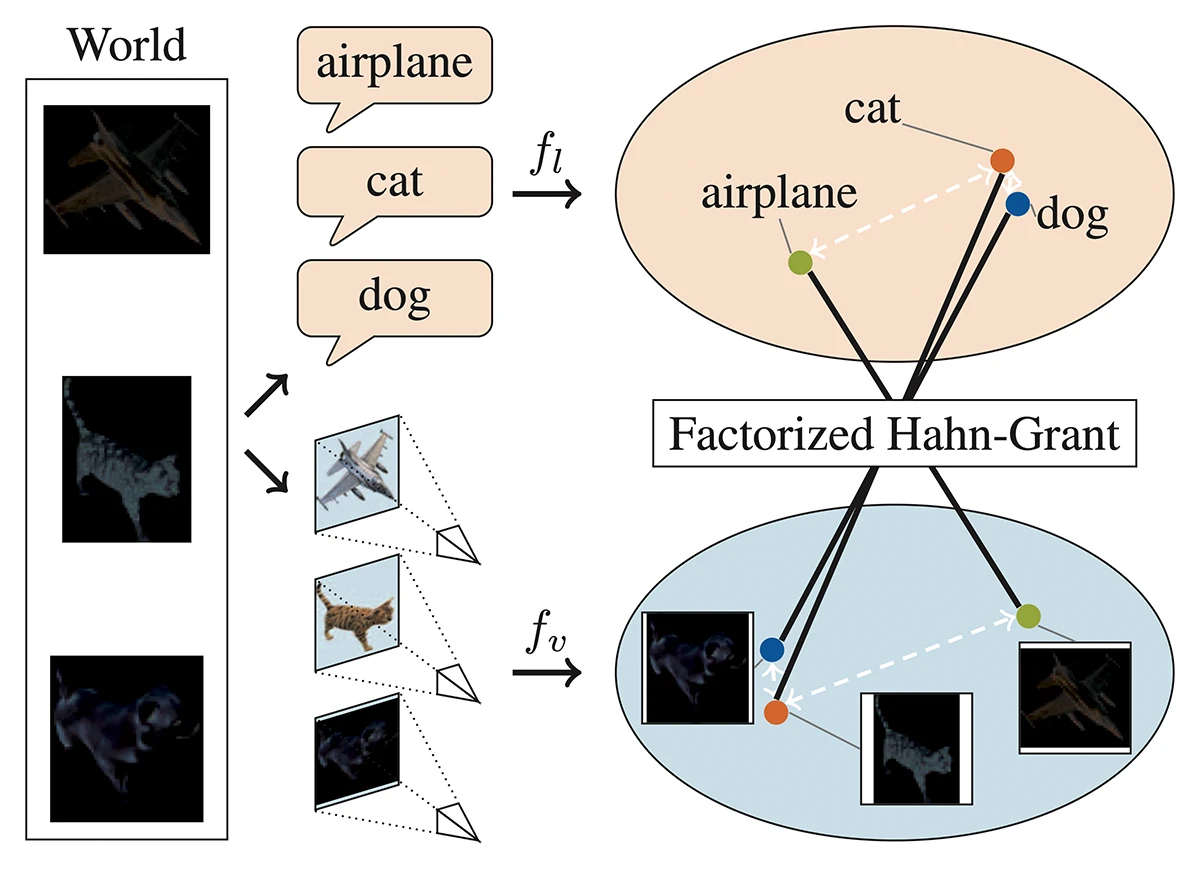
©Schnaus et al.
Figure 1: Blind matching of vision and language: Text and images are both abstractions of the same underlying world. Vision and language encoders fv and fl learn similar pairwise relations between concepts, e.g. "cat" is closer to "dog" than to "airplane". They exploit these pairwise relations in their factorized Hahn-Grant solver to find valid correspondences between vision and language without any parallel data.
The Idea Behind the Paper
Modern vision and language models are trained separately on massive datasets, yet they often learn surprisingly similar structures about the world. For example, like how images of cats sit closer to dogs than airplanes, the text embeddings for “cat” and “dog” are also closer than “cat” and “airplane”.
This echoes the Platonic Representation Hypothesis, which says that bigger models tend to learn more similar “shapes” of concepts. If this is true, then vision and language models might already organise ideas in comparable ways and so we could match them without any image–text pairs, just by looking at how their embeddings are arranged.
The core idea of the paper is simple: take two sets of points, one from images, one from text, and ignore their labels entirely. All you look at are the distances inside each set: which concepts sit close together and which are far apart. If vision and language models encode the world in similar ways, the overall “shape” of these two spaces should match. The solver then tries to align these shapes by comparing their distance patterns and finding the permutation that makes them line up, revealing which image concept corresponds to which word. No captions, no labels: just geometry.
«Our analysis reveals that for many problem instances, vision and language representations can be indeed matched without supervision. This finding opens up the exciting possibility of embedding semantic knowledge into other modalities virtually annotation-free.»
Dominik Schnaus et al.
MCML Junior Members
Results
The authors evaluate 33 vision models (like DINO, DINOv2, CLIP, ConvNeXt, DeiT) and 27 language models across four benchmarks to test their hypothesis. The results were surprisingly strong, with small category sets matched very well, and slightly bigger category sets matched reliably well. They found that overall, vision and language spaces already share a deeply similar internal geometry which can be utilised.
«Our larger-scale experiments show that vision and language models may encode semantic concepts differently. This is not surprising, since some concepts are abstract and appear only in one of the modalities, e.g. "freedom of speech"»
Dominik Schnaus et al.
MCML Junior Members
Why It Matters
These findings show that vision and language models, even trained completely separately, still learn compatible structures of the world. This unlocks exciting implications:
- Cross-modal alignment may not require paired datasets
- Unsupervised labeling and categorization become possible
- Semantic information could be transferred from text to images without supervision
In short, blind matching offers a path toward multimodal learning that is simpler, cheaper, and far less dependent on human-annotated image–text pairs.
Challenges and Next Steps
Despite strong results, challenges remain: matching becomes harder with more categories, some concepts exist only in one modality, and the optimization is costly and doesn’t yet scale to very large sets. Fine-grained or abstract classes can also break alignment when their geometry differs across models. The authors hope that this established feasibility creates new avenues for applications in vision language models, which continue to get more and more robust.
Further Reading & Reference
If you’d like to explore how blind vision–language matching works in practice, take a look at the paper presented at CVPR 2025—one of the leading international conferences in computer vision—and explore the accompanying code and project page.
It's a (Blind) Match! Towards Vision-Language Correspondence without Parallel Data.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

02.04.2026
How AI Avatars Shape Perceived Fairness
Accepted at CHI 2026, this study shows how the race and gender of AI interview avatars shape perceptions of fairness and bias in automated hiring.

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

