10.07.2025

Capturing Complexity in Surgical Environments
MCML Research Insight - With Ege Özsoy, Chantal Pellegrini, Felix Tristram, Kun Yuan, David Bani-Harouni, Matthias Keicher, Benjamin Busam and Nassir Navab
Imagine an operating room - a space filled with intricate interactions, rapid decisions, and precise movements. Now, imagine capturing every detail of such a complex environment not just visually but also through sound, dialogue, robot movements, and much more. This is exactly what MM-OR – A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments accomplishes.
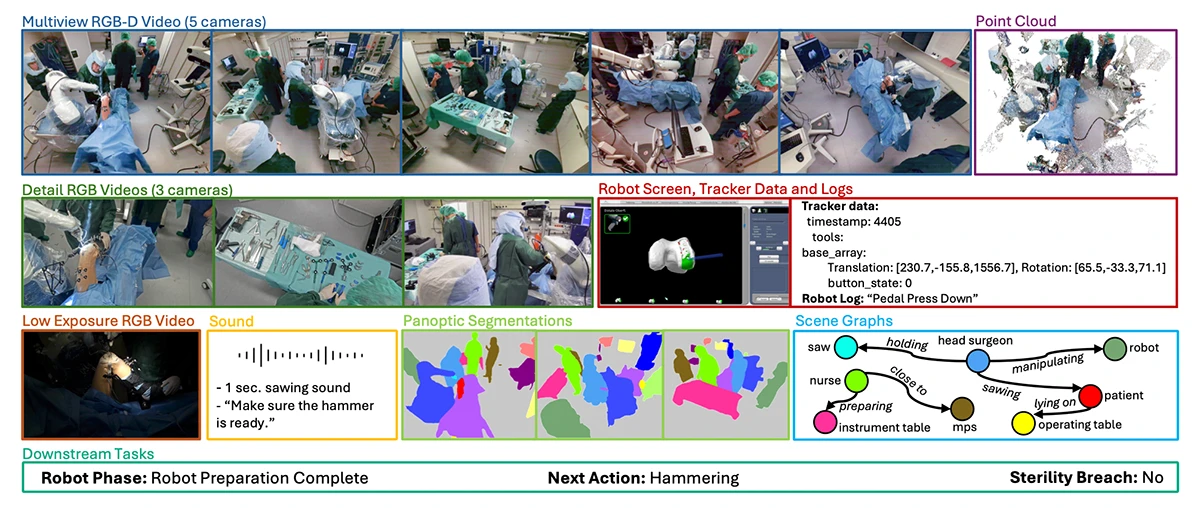
©Özsoy et al.
Figure 1: Visual Summary of a single timepoint in MM-OR, illustrating the multimodal data provided for each sample: RGB-D video from multiple angles, detailed RGB views, low-exposure video, point cloud data, robot screen and tracker logs, audio and speech transcripts, panoptic segmentations, semantic scene graphs, and downstream task annotations such as robot phase, next action, and sterility breach status.
Introduced in a CVPR 2025 paper by MCML Junior Members Ege Özsoy, Chantal Pellegrini, Felix Tristram, Kun Yuan, David Bani-Harouni, Benjamin Busam and Matthias Keicher, MCML PI Nassir Navab and collaborators Tobias Czempiel and Ulrich Eck, MM-OR is a comprehensive multimodal dataset created to significantly enhance our understanding of operating room (OR) dynamics. It captures robotic knee replacement surgeries (see Figure 1) using various sophisticated sensors, including multiple RGB-D cameras, audio recorders, infrared trackers, and real-time robotic system logs.
Semantic Scene Graph Generation With MM2SG
This detailed data collection allows for generating semantic scene graphs - structured representations of interactions between people, tools, and equipment in the OR. Alongside this, the researchers present MM2SG, an innovative multimodal model capable of interpreting and integrating diverse data types to generate detailed semantic scene graphs that accurately represent OR activities (see Figure 2).

©Özsoy et al.
Figure 2: Overview of the proposed MM2SG architecture for multimodal scene graph generation. MM2SG processes a variety of data sources through specialized encoders, projecting them into a shared space. The language model generates scene graph triplets describing SGs with entities E i and predicates p i . Downstream tasks leverage entire sequences of scene graphs rather than individual ones.
«This research is laying a foundation for advancing multimodal scene analysis in high-stakes environments.»
Ege Özsoy et al.
MCML Junior Members
A New Benchmark
What sets MM-OR apart from existing datasets is its unprecedented scale, realism, and multimodality, significantly surpassing previous efforts that often suffered from limited size, narrow scope, or lack of diverse data types. By providing panoptic segmentation annotations and supporting complex downstream tasks like sterility breach detection and action anticipation, MM-OR establishes a robust new benchmark for evaluating and developing advanced OR modeling techniques.
Open Challenges
Despite these advancements, open challenges remain, including accurately modeling rare surgical actions and effectively generalizing models to diverse surgical scenarios beyond knee replacement procedures.
Why It Matters
Because better understanding of surgical environments means enhanced situational awareness, improved safety, and more effective surgical assistance.
Curious to Explore More?
The full paper published at the CVPR 2025, one of the highest-ranked AI/ML conferences, provides a more in-depth exploration of the potential of this new dataset and technology, laying the foundations for future advancements in OR systems.
MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Also check out the YouTube Video showing the dataset.
Additional Material: Practical Examples and Recording Setup
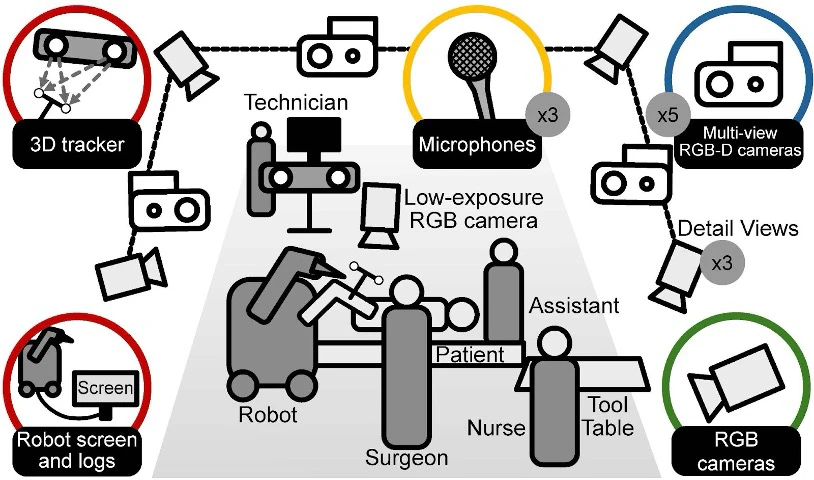
©Özsoy et al.
Figure 3: Recording setup and sensors overview. A grey circle by each sensor shows quantity; if absent, the sensor count is one.
To provide deeper insights into how MM-OR and MM2SG work in practice, the following visuals illustrate the technical setup used to collect such comprehensive data (see Figure 3) and showcase a real example of MM2SG generated outputs (see Figure 4).

©Özsoy et al.
Figure 4: Qualitative examples from a test take in MM-OR, illustrating scene graph generation performance of MM2SG. Unlabeled edges indicate the ”close to” predicate.
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

09.07.2026
MCML Junior Member Bolei Ma Earns Best Paper and SAC Highlight Awards at ACL 2026
Bolei Ma receives a Best Paper Award and an SAC Highlight Award at ACL 2026 for outstanding contributions to NLP research.

08.07.2026
How Autonomous Systems Learn to Understand Their Environment
The team at the startup SE3 Labs has developed a spatial AI technology that uses images, videos, and map data to create realistic 3D models.

08.07.2026
MCML Junior Member Sarah Ball Receives Outstanding Position Paper Award at ICML 2026
MCML Junior Member Sarah Ball and her co-author Phil Hackemann received the Outstanding Position Paper Award at ICML 2026 this week in Seoul.

