20.06.2025

Zooming in on Moments: ReVisionLLM for Long-Form Video Understanding
MCML Research Insight - With Tanveer Hannan and Thomas Seidl
Imagine watching a two-hour video and trying to find the exact moment someone scores a goal - or says something important. Humans can do this with ease by skimming and zooming in. But for AI, finding specific moments in long videos is incredibly hard.
Most current AI systems struggle to handle more than a few minutes of video at a time. They often miss the forest for the trees - either losing detail or skipping over important moments. That's where ReVisionLLM comes in.
ReVisionLLM, developed by MCML Junior Member Tanveer Hannan, MCML Director Thomas Seidl and collaborators Md Mohaiminul Islam, Jindong Gu and Gedas Bertasius, mimics how humans search through content: by starting broad, identifying interesting segments, and then zooming in recursively to locate precise start and end points of an event.
«To our knowledge, ReVision-LLM is the first VLM capable of temporal grounding in hour-long videos.»
Tanveer Hannan
MCML Junior Member
Why Temporal Grounding Matters
From surveillance and sports analytics to educational video search, the ability to link language queries to exact video moments, called temporal grounding, is a major step toward intelligent video understanding. But scaling this to hours of footage is extremely hard due to memory limits, dense video data, and noisy confidence estimates.
Recursive, Just Like Us
ReVisionLLM uses a hierarchical strategy inspired by cognitive science. It processes video in layers, from coarse to fine, narrowing down the relevant segments at each stage. First, it identifies promising multi-minute chunks, then drills down to short spans of just a few seconds. This recursive structure allows the model to work efficiently without processing every single frame at once.
©Hannan et al.
Recursive Video Grounding: ReVisionLLM is a recursive vision-language model designed for localizing events in hourlong videos. Inspired by human search strategies, it first scans the entire video to identify relevant intermediate segments and then zooms in to precisely locate event boundaries. Here, we show one intermediate hierarchy for brevity.
©Hannan et al.
Existing vision-language models (VLMs) such as VTimeLLM are not equipped to process hour-long videos effectively and struggle to pinpoint precise temporal boundaries for events within extended video durations. In contrast, ReVision-LLM is the first VLM designed to address this limitation, enabling accurate temporal grounding in hour-long video content.
«Our model significantly outperforms previous state-of-the-art approaches, surpassing specialized models and other VLMs on multiple datasets by a substantial margin.»
Tanveer Hannan
MCML Junior Member
So, What Can It Do?
- Handles videos of any length, from minutes to hours
- Follows natural language instructions to locate events
- Outperforms previous models on major benchmarks like MAD and VidChapters
With ReVisionLLM, machines are getting closer to understanding video the way humans do - patiently, efficiently, and with precision.
Curious to Learn More About ReVisionLLM and How It Is Trained?
Check out the full paper presented at the prestigious A* conference CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition:
ReVisionLLM: Recursive Vision-Language Model for Temporal Grounding in Hour-Long Videos.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Additional Material

©Hannan et al.
Qualitative results on MAD. ReVisionLLM accurately locates precise event boundaries that involve intricate actions (top) and complex visual details (bottom) within hour-long movies. In contrast, our VLM baseline fails entirely to capture these events.
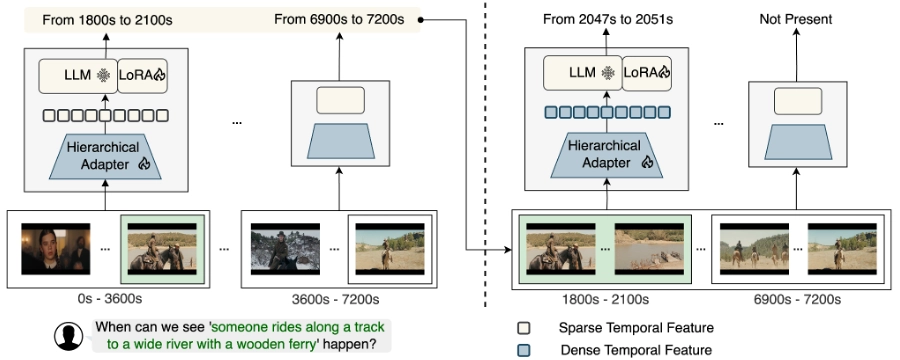
©Hannan et al.
The ReVisionLLM model. (Left) First, we detect segments (e.g., a few minutes) from an hour-long video using sparse temporal features produced by the Hierarchical Adapter. (Right) Then ReVisionLLM produces a precise temporal boundary using dense temporal features within the predicted segments. Note that the green box represents the same event boundary in both sub-figures, zooming in from left to right. The multimodal encoder is omitted for simplicity.

©Hannan et al.
Progressive Training Method. Our model is trained progressively: first on short video segments and then on hour-long videos. (Left) In the first stage, the model learns to detect whether an event is present in the input video and, if so, predicts its precise start and endpoints. Sparse features help determine an event’s presence, while dense features additionally facilitate exact localization. (Right) In the second stage, we utilize the sparse features learned in Stage 1 to identify event segments within hour-long videos.
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

