03.04.2025

CUPS: Teaching AI to Understand Scenes Without Human Labels
MCML Research Insight - With Christoph Reich, Nikita Araslanov, and Daniel Cremers
Understanding the location and semantics of objects in a scene is a significant task, enabling robots to navigate through complex environments or facilitating autonomous driving. Recent AI models for understanding scenes from images require significant guidance from humans in the form of pixel-level annotations to achieve accurate predictions.
To overcome the reliance on human guidance, our Junior Members - Christoph Reich and Nikita Araslanov - together with MCML Director Daniel Cremers and collaborators Oliver Hahn, Christian Rupprecht, and Stefan Roth from TU Darmstadt and the University of Oxford, proposed a novel approach: 🥤🥤 CUPS: Scene-Centric Unsupervised Panoptic Segmentation.
«We present the first unsupervised panoptic method that directly trains on scene-centric imagery.»
Christoph Reich et al.
MCML Junior Members
Why Unsupervised Segmentation Matters
The vast majority of current AI models for segmenting and localizing objects in an image are supervised. This means humans must collect a large dataset of hundreds or thousands of images and manually annotate every pixel of each image. Equipped with these annotated example images, an AI model can be trained. The annotation process, however, is immensely time and resource-intensive. Additionally, human annotations can entail significant biases.
Overcoming the need for annotated data circumvents the time and resource-intensive human annotation process and does not introduce annotation biases. CUPS builds the first approach to segmenting and localizing objects in images of complex scenes, including a vast number of objects, without requiring human annotations for training.
«We derive high-quality panoptic pseudo labels of scene-centric images by leveraging self-supervised visual representations, depth, and motion.»
Christoph Reich et al.
MCML Junior Members
How to Segment Images Without Human Supervision
Humans group visual elements and objects based on specific perceptual cues. These cues include (1) similarity; grouping objects based on their similarity; (2) invariance, recognizing objects independent of their rotation, translation, or scale; and (3) common fate, elements that move together belong to the same object. CUPS builds on these perceptual cues to obtain unsupervised pseudo-labels. In particular, optical flow, depth, and visual representations are used to detect objects and obtain semantics. This object and semantic-level understanding is called panoptic segmentation.
Key Benefits of CUPS

©Christoph Reich et al.
Motion and depth are used to generate scene-centric panoptic pseudo-labels. Given a monocular image (bottom right), CUPS learns a panoptic network using pseudo labels and self-training.
«Our approach brings the quality of unsupervised panoptic, instance, and semantic segmentation to a new level.»
Christoph Reich et al.
MCML Junior Members
Using these pseudo-labels, CUPS first trains a panoptic segmentation network that both detects objects and predicts semantic categories. After training using pseudo-labels, CUPS performs self-training, which enables the panoptic network to detect objects not captured by the pseudo-labels and enhances the network’s segmentation accuracy.
- Unsupervised Panoptic Segmentation - CUPS does not require any human annotations to perform segmentation
- Scene-Centric Performance - Accurate segmentations on complex scenes, including a large number of objects
- Competitive Results - CUPS archives state-of-the-art segmentation accuracy across multiple benchmarks, outperforming existing unsupervised models
CUPS in Action
The CUPS approach achieves impressive segmentation results on various datasets. Compared to a recent approach (U2Seg), CUPS detects more objects (e.g., persons and cars) and better captures the semantics of a scene (e.g., distinguishes between road and sidewalk). Quantitatively, CUPS significantly improves segmentation accuracy.
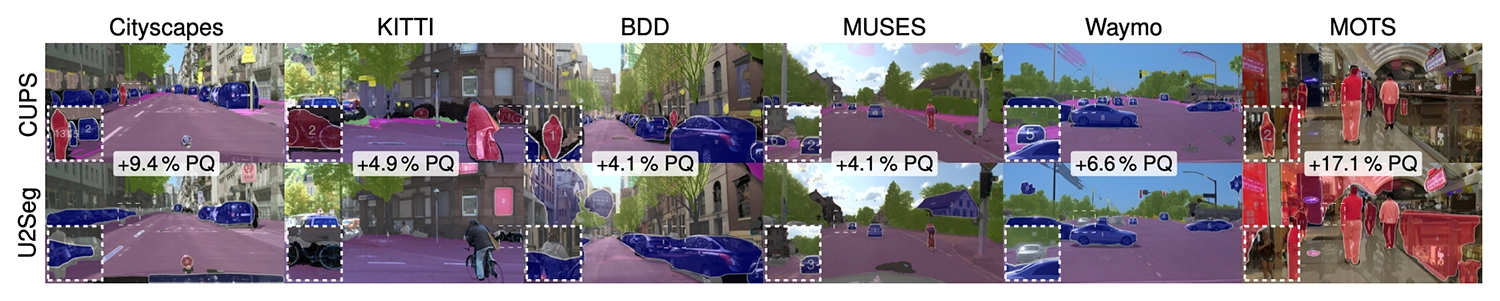
©Christoph Reich et al.
CUPS in action. Given a single image of a crowded scene, CUPS predicts accurate panoptic segmentations, while the recent U2Seg model struggles.
Further Reading & Reference
While this blog post highlights the core ideas of CUPS, the respective CVPR 2025 paper takes a deep look at the entire methodology - including how pseudo-labels are generated and training is performed.
If you’re interested in how CUPS compares to other unsupervised and supervised segmentation methods - or want to explore the technical innovations behind its strong performance - check out the full paper accepted to CVPR 2025, one of the most prestigious conferences in the field of computer vision.
Scene-Centric Unsupervised Panoptic Segmentation.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Curious to test CUPS on your images? The code is open-source - check out the GitHub repository and experience CUPS by checking out the example video below.
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

