27.03.2025

Beyond the Black Box: Choosing the Right Feature Importance Method
MCML Research Insight - With Fiona Katharina Ewald, Ludwig Bothmann, Giuseppe Casalicchio and Bernd Bischl
Machine learning models make powerful predictions, but can we really trust them if we don’t understand how they work? Global feature importance methods help us discover which factors really matter - but choosing the wrong method can lead to misleading conclusions. To see why this is important, consider a real-world example from medicine.
«Since the results of different feature importance methods have different interpretations, selecting the correct feature importance method for a concrete use case is crucial and still requires expert knowledge.»
Fiona K. Ewald et al.
MCML Junior Members
Imagine a doctor trying to diagnose a disease using a set of biomarkers—biological measurements that indicate a person’s health. Some biomarkers, like blood pressure or cholesterol levels, are crucial for determining the disease, while others might be unrelated or even misleading. But how does the doctor figure out which ones truly matter?
This is exactly the kind of challenge scientists face when using machine learning models. These models have the potential to make incredibly accurate predictions, but they often function as “black boxes” – meaning we don’t always understand why they make certain decisions.
To understand these decisions, feature importance methods come into play. A recent paper, “A Guide to Feature Importance Methods for Scientific Inference,” developed by our MCML Junior Members Fiona Katharina Ewald, Ludwig Bothmann, Giuseppe Casalicchio, our Director Bernd Bischl, and collaborators Marvin N. Wright and Gunnar König, explores this issue in depth. The goal of the paper is to provide a clear, structured guide to different feature importance methods to help researchers and practitioners choose the right technique when interpreting AI models. Understanding these methods is crucial, especially in fields like medicine.
How to Measure Feature Importance
The paper outlines several feature importance methods, each with a different way of assessing which feature (e.g., cholesterol levels) is important. They mainly differ in two aspects:
- How they remove a feature’s information and
- How they compare model performance before and after feature removal
«Understanding the data generating process requires insights into feature-target associations, which many machine learning models cannot directly provide due to their opaque internal mechanisms.»
Fiona K. Ewald et al.
MCML Junior Members
Regarding the first aspect, some methods eliminate the feature completely and retrain the model without it. Other approaches perturb the feature values individually or marginalize over all other features (either based on marginal distributions or conditional distributions, thereby preserving relationships among features).
Concerning the second aspect, some methods measure the decline in performance when a specific feature is removed from the full model (containing all features). Other approaches assess the gain in performance achieved when using only the feature of interest compared to an empty model (a model without any features, typically a constant prediction such as the average target value). Finally, certain techniques (e.g., Shapley-based ones) quantify a feature’s importance by averaging its incremental contribution when added to various subsets of features.
Two well-known and simple examples are Permutation Feature Importance (PFI) and Leave-One-Covariate-Out (LOCO). Both methods assess whether the model’s predictions worsen when removing a feature’s information compared to the full model, but they differ in how they remove the information. While PFI randomly shuffles the values of a feature to destroy the feature-target relationship, LOCO retrains the entire model without a feature. If removing the information of a feature (say, blood pressure) causes a huge drop in accuracy, it means that the feature was important. Unfortunately, PFI recently went out of fashion.
Why Some Importance Methods Give Conflicting Results
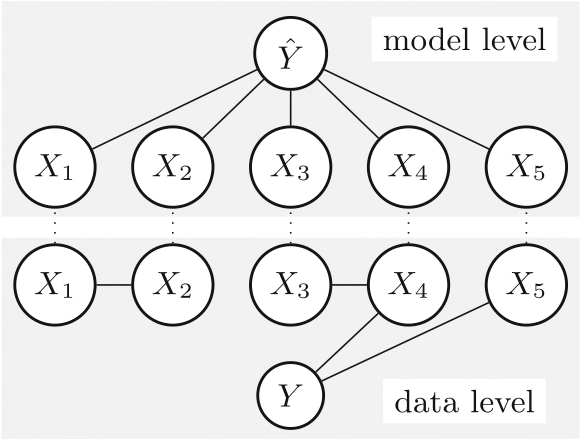
©Fiona K. Ewald et al.
A conceptual illustration of AI decision-making. The data level (bottom) represents the true relationships between features (e.g., biomarkers) and the outcome (disease). The model level (top) represents how an AI system processes these features to make a prediction. Feature importance methods help bridge the gap between these levels by revealing which inputs truly matter.
Imagine that the doctor runs two different feature importance methods (e.g., PFI and LOCO) to determine which biomarkers are most important for an applied ML model. Interestingly, these give conflicting results - one method ranks cholesterol as the most critical, while the other suggests that blood pressure is far more important. What’s going on?
As described above, the feature importance methods differ in their computation and thus measure different types of relationships between features (biomarkers) and the prediction target (the disease). The paper discusses in detail which feature importance method measures which kind of feature-target association, which fall into two main categories:
- Unconditional Association – A biomarker is considered unconditionally important if, on its own, it helps predict the disease even if no other information (from other biomarkers) is known. If the biomarker and the disease have no connection, then this type of association does not exist.
- Conditional Association – A biomarker is conditionally important if it still provides valuable information even when we already have information on other features related to the disease. This means that its significance is not just due to its direct effect but also how it interacts with or complements other known information.
«No Feature Importance score can simultaneously provide insight into more than one type of association.»
Fiona K. Ewald et al.
MCML Junior Members
In machine learning, researchers often focus on a specific type of conditional association: whether a biomarker still plays a role in prediction even after considering all other available factors. This is crucial because some biomarkers may seem important at first but lose their relevance once other related factors are considered.
Coming back to our two feature importance measures mentioned above:
- PFI: If some assumptions about the data are fulfilled, PFI theoretically provides insights into unconditional associations. However, it sometimes mistakenly highlights features that are only correlated with other features (not the target) rather than those that directly affect the disease.
- LOCO: This method is theoretically great for finding features conditionally associated with a target.
Different feature importance methods detect different types of associations, which explains why results can vary. Unfortunately, not every method measures the theoretical constructs explained above exactly. Additionally, we do not even have enough insights on some newer techniques to characterize them properly statistically.
Why This Matters
Choosing a proper feature importance method isn’t just a technical detail - it has real-world consequences. It requires not only understanding how a method works but also understanding which implications different types of computations have. If a doctor mistakenly relies on a misleading biomarker due to the misinterpretation of a certain feature importance method, patients might receive the wrong treatment. Similarly, if scientists misinterpret the result or choose the wrong feature importance method, they could draw incorrect conclusions about what truly matters. By carefully selecting the appropriate method, we can move beyond black-box models and make more informed, trustworthy decisions.
Tools to Try & Dive Deeper
Want to experiment with feature importance techniques yourself? While the experiments in the paper were performed using the Python library fippy, there are many more packages in R and Python that provide implementations of feature importance methods:
Method | R | Python |
PFI | iml, cpi, vip, ingedients, dalex | |
CFI | ||
RFI | - | |
LOCO | ||
SAGE | - |
Read More
While this article introduces key concepts, the original paper explores a broader range of methods, offering detailed mathematical insights and practical recommendations for selecting the right approach. If you want to gain a deeper understanding of how different feature importance techniques work and when to use them, check out the full paper published at xAI 2024:
A Guide to Feature Importance Methods for Scientific Inference.
xAI 2024 - 2nd World Conference on Explainable Artificial Intelligence. Valletta, Malta, Jul 17-19, 2024. DOI
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

