27.11.2025

Seeing the Bigger Picture – One Detail at a Time
MCML Research Insight - With Rui Xiao, Sanghwan Kim, and Zeynep Akata
Large vision-language models (VLMs) like CLIP (Contrastive Language-Image Pre-training) have changed how AI works with mixed inputs of images and text, by learning to connect pictures and words. Given an image with a caption like “a dog playing with a ball”, CLIP learns to link visual patterns (the dog, the ball, the grass) with the words in the caption. This lets it recognize and describe new images it has never seen before, a skill known as zero-shot learning.
«Our model introduces text-conditioned attention pooling on top of local image tokens to produce fine-grained image representations that excel at retrieving detailed image content.»
Rui Xiao et al.
MCML Junior Members
But CLIP tends to see the world in broad strokes and matches the whole image to the whole caption. Ask it to find “the red flower on the left” or “a smiling dinosaur”, and it might miss or confuse them. It knows what the image shows, but not where or how things appear.
In their CVPR 2025 paper “FLAIR: VLM with Fine-grained Language-informed Image Representations”, MCML Junior Members Rui Xiao and Sanghwan Kim, and former members Stephan Alaniz and Mariana-Iuliana Georgescu, with MCML PI Zeynep Akata, address this challenge. They developed FLAIR, a new approach which helps models focus on small, meaningful details by letting the text guide where they look.
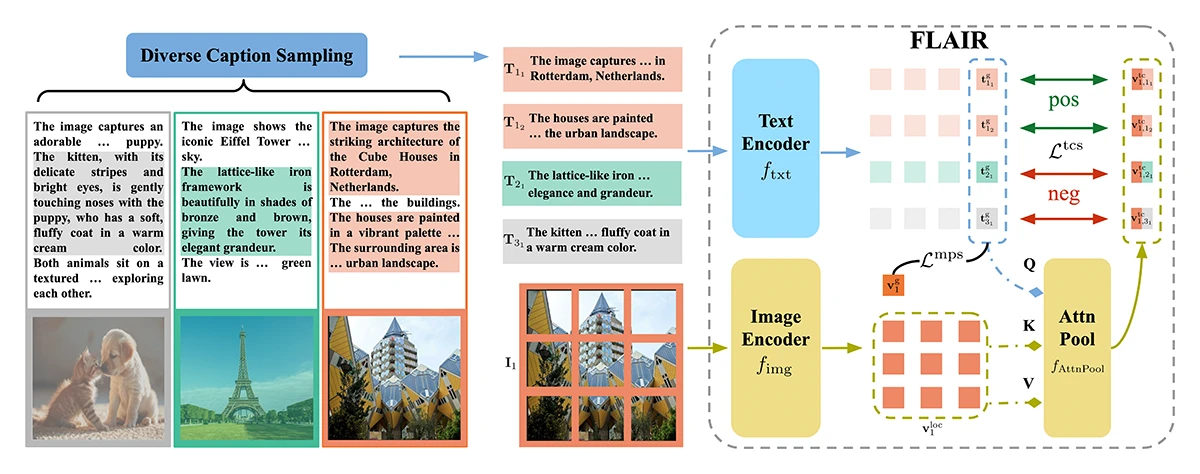
©Xiao et al.
Figure 1: Overview of the FLAIR framework. (A) Diverse Caption Sampling: each image is paired with long, descriptive captions that are split into multiple shorter ones capturing local details such as color, texture, or objects. (B) Model structure: the text encoder and image encoder process captions and image patches separately. A text-conditioned attention pooling module then combines them, producing fine-grained, language-guided image representations. (C) Learning objective: the text-conditioned sigmoid loss aligns text and image features at a local level, while the multi-positive sigmoid loss refines global alignment.
How It Works
Think of CLIP as a student who reads the caption “a cat sitting on a red sofa” and then tries to understand the whole picture at once. FLAIR, on the other hand, is like a student who reads the same caption and then looks at the exact parts of the image that mention “cat” and “red sofa”. FLAIR does this by using text-conditioned attention pooling, which is a way of letting the text guide the model’s focus inside the image. It divides the image into many small patches, each representing a part (like the cat, sofa, or background). The caption acts like a question: “Which parts match me?” The model then highlights those relevant regions.
To train FLAIR, the team used long, descriptive captions generated by multimodal language models, like ones that say things like “The kitten, with its delicate stripes and bright eyes, is gently touching noses with the puppy, who has a soft, fluffy coat in a warm cream color”. Each long caption is split into smaller ones, each describing one detail, so the model learns both the overall scene and the local parts.

©Xiao et al.
Figure 2: Visualization of attention maps in the attention pooling layer fAttnPool. Regions of high attention are highlighted in red.
What Makes It Different
What makes FLAIR much more effective than CLIP is that it combines two ideas during training:
- Text-conditioned learning – The image features are shaped by the words. Each caption teaches the model to focus only on the matching visual region.
- Multi-level learning – The model doesn’t forget the big picture. It learns both the small details and the full image, keeping global understanding intact.
This double focus helps FLAIR understand images more precisely, it can zoom in the images without losing context.
Results
The results are quite promising, despite being trained on just 30 million image–text pairs (far fewer than CLIP’s billions) FLAIR performs even better on many tasks.
It finds the right image for a short, specific caption up to 10%–11% more accurately than previous CLIP models. Even with a smaller dataset, it handles long, multi-sentence descriptions much better and highlights the right parts of an image with over 14% improvement on average. In short, FLAIR “looks” where it’s supposed to when it comes to linking words and visual details with striking precision.
«The significant improvements in zero-shot segmentation compared to the baselines as well as the qualitative results corroborate that FLAIR learns a fine-grained alignment between text and image at the token-level.»
Rui Xiao et al.
MCML Junior Members
Why It Matters
As AI tools become part of daily life, they need to understand not just what is in a scene but also where and how things appear. FLAIR adds that missing focus. By combining language and detailed vision, it helps make AI more attentive, transparent and efficient.
Challenges and Next Steps
While FLAIR captures details impressively, scaling it up to the same size as billion-sample models could make it even more powerful. The team plans to expand its training to larger datasets and explore how these fine-grained features could help other tasks like scene understanding and object detection.
Further Reading & Reference
If you’d like to explore how FLAIR helps AI see with more precision, check out the full paper appeared at the prestigious A* conference CVPR 2025.
FLAIR: VLM with Fine-grained Language-informed Image Representations.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

23.03.2026
MCML at EACL 2026
MCML researchers are represented with 13 papers at EACL 2026 (9 Main, and 4 Findings).

