20.11.2025

Zigzag Your Way to Faster, Smarter AI Image Generation
MCML Research Insight - With Vincent Tao Hu, Olga Grebenkova, Pingchuan Ma, Johannes Schusterbauer, and Björn Ommer
State-of-the-art diffusion models like DiT and Stable Diffusion have made AI image generation incredibly powerful. But they still struggle with one big issue: scaling to large images or videos quickly and efficiently without exhausting your GPU memory. What if we could process images faster, use less memory, and still retain visual quality—without sacrificing the model’s expressiveness?
The paper from MCML Junior Members Vincent Tao Hu, Olga Grebenkova, Pingchuan Ma, Johannes Schusterbauer, and MCML PI Björn Ommer, and collaborators Stefan Andreas Baumann, and Ming Gui, introduces ZigMa, a plug-and-play diffusion backbone that combines the strengths of DiT-style architectures and Mamba’s efficient long-range sequence modeling.
«Our Zigzag Mamba method injects spatial continuity into Mamba’s scanning process, enabling high-resolution image and video generation with lower complexity.»
Vincent Tao Hu et al.
MCML Junior Members
The Insight: Scan Like a Human, Not Like a CPU
Mamba is a new state-space model (SSM) that can model long sequences very efficiently. But most vision models treat 2D images like flat 1D sequences using computer-style scanning (row-by-row or column-by-column). This breaks spatial continuity—like reading a painting line-by-line instead of seeing the whole picture.
The authors realized that this scan order matters a lot. So they designed Zigzag Scanning: a spatially continuous path that mimics how humans process visual information—preserving neighborhoods and image structure layer by layer (see Figure 1).
By combining this zigzag path with Mamba blocks in a DiT-style backbone, the team created a model that’s both memory-efficient and faster—without sacrificing expressiveness.
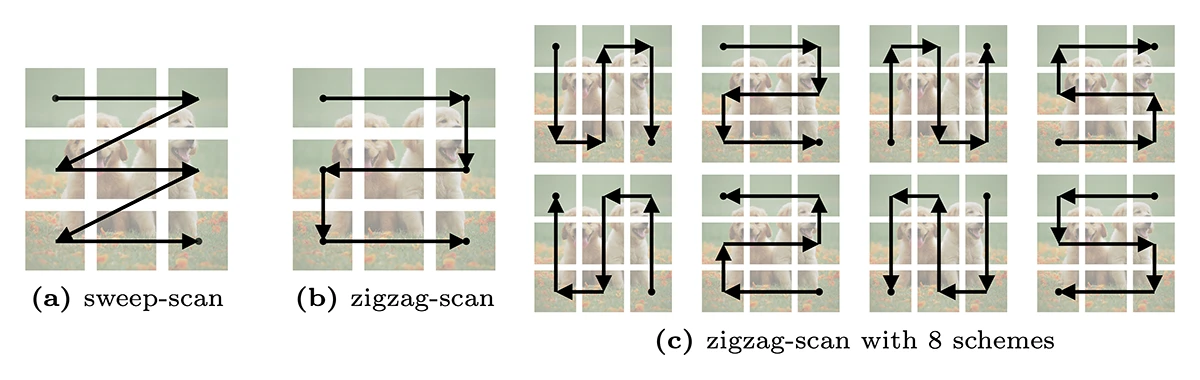
©Hu et al.
Figure 1: The 2D Image Scan. Our mamba scan design is based on the sweep-scan scheme shown in subfigure (a). From this, we developed a zigzag-scan scheme displayed in subfigure (b) to enhance the continuity of the patches, thereby maximizing the potential of the Mamba block. Since there are several possible arrangements for these continuous scans, we have listed the eight most common zigzag-scans in subfigure (c).
«We introduce the notion of Order Receptive Field—the number of zigzag paths used across layers—to balance quality, speed, and memory.»
Vincent Tao Hu et al.
MCML Junior Members
Zigzag Mamba: A Drop-in Replacement for Transformers
The core component of ZigMa is a zero-parameter heterogeneous layerwise scan:
- Each layer uses a different zigzag scan path from a pre-designed set (like S[i % 8])
- The scan paths are spatially continuous and inductively aligned with natural images
- No extra computation or parameters are introduced compared to standard Mamba
- Cross-attention blocks are added for text conditioning, enabling T2I generation
This simple yet powerful design outperforms both Transformer-based (DiT, U-ViT) and SSM-based (VisionMamba) baselines on high-res datasets like FacesHQ (1024×1024) and MS COCO.
«Our method can consistently maintain GPU efficiency as the number of scan paths increases—unlike Transformer-based or k-direction Mamba models.»
Vincent Tao Hu et al.
MCML Junior Members
Why It Matters: High-Resolution, Low-Overhead Generation
ZigMa pushes the boundary of scalability in diffusion models:
- Images: Trained on 1024×1024 CelebA-HQ+FFHQ (FacesHQ), ZigMa outperforms VisionMamba with higher batch sizes and better utilization
- Videos: On UCF101, ZigMa achieves superior FVD scores with fewer parameters, using a factorized 3D Zigzag Mamba design
- Speed & Memory: ZigMa requires ~40% less GPU memory than DiT or U-ViT while delivering higher FPS, even with 8 scan paths
Theoretical Backing: Stochastic Interpolant
ZigMa is not just about clever scanning—it’s built on a strong probabilistic foundation.
By adopting the Stochastic Interpolant framework [Albergo et al.], the model learns to estimate both the score function and the velocity vector for sampling under diffusion or flow-based formulations. This allows ZigMa to support both SDE and ODE samplers, enabling faster sampling without retraining.
TL;DR
ZigMa shows that how you scan matters. A simple change—like scanning in a zigzag—can drastically improve the performance of generative models. It’s a plug-and-play improvement that works out of the box with diffusion frameworks, scaling from images to videos, and retaining compatibility with text-conditioning.
Explore the Code, Paper & Demo
Check out the full paper appeared at ECCV 2024, one of the top-tier (A*) conferences in computer vision, where the team presents the complete method and results.
ZigMa: A DiT-style Zigzag Mamba Diffusion Model.
ECCV 2024 - 18th European Conference on Computer Vision. Milano, Italy, Sep 29-Oct 04, 2024. DOI GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

