25.09.2025

Compress Then Explain: Faster, Steadier AI Explanations - With One Tiny Step
MCML Research Insight - With Giuseppe Casalicchio and Bernd Bischl
Imagine re-running feature importance plots and getting slightly different “top features.” Annoying, right? That uncertainty often comes from a quiet assumption: model explanation algorithms typically sample points from data at random.
A new ICLR 2025 Spotlight paper by MCML Junior Member Giuseppe Casalicchio, MCML Director Bernd Bischl, first author Hubert Baniecki and co-author Przemyslaw Biecek flips this script with a simple idea: compress your data distribution first, then explain the model. The authors call it Compress Then Explain (CTE) and it consistently makes explanations more accurate, more stable, and much faster.
©Baniecki et al.
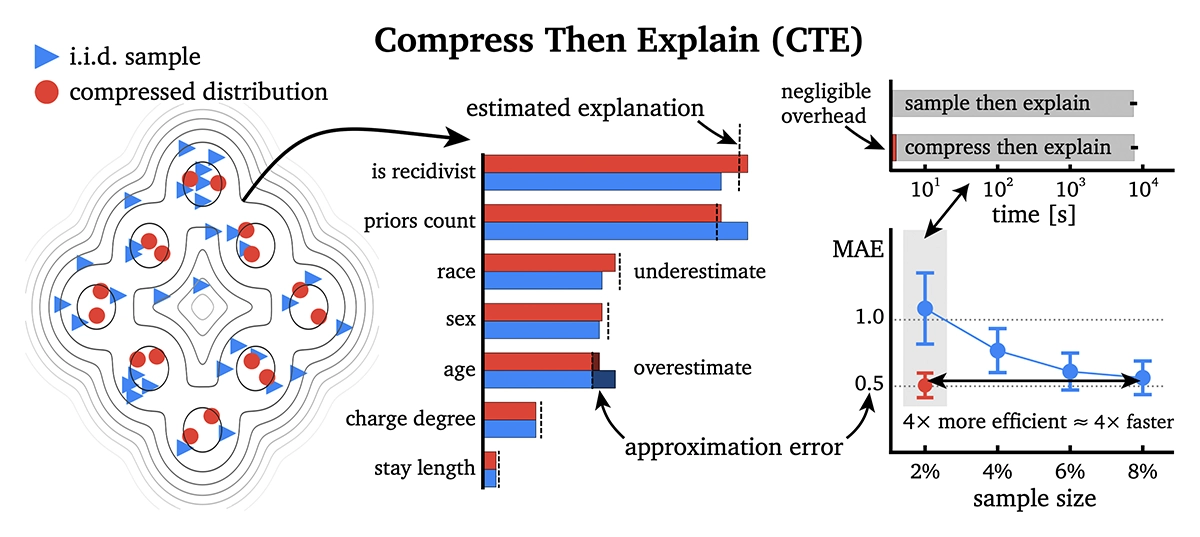
Figure 1: Garbage sample in, garbage explanation out. Sample then explain is a conventional approach to decrease the computational cost of explanation estimation. Although fast, sampling is inefficient and prone to error, which may even lead to changes in feature importance rankings. The authors propose compress then explain (CTE), a new paradigm for accurate, yet efficient, estimation of explanations based on a marginal distribution that is compressed, e.g. with kernel thinning.
«CTE often achieves on-par error using 2–3× fewer samples, i.e., requiring 2–3× fewer model inferences. CTE is a simple, yet powerful, plug-in for a broad class of methods that sample from a dataset, e.g. removal-based and global explanations.»
Giuseppe Casalicchio
MCML Junior Member
Why This Matters
Modern explainers (SHAP, SAGE, expected gradients, feature effects) often need a background/reference set. When those points are drawn independently and identically distributed (i.i.d.) at random, you get estimation noise that can distort attributions and even reshuffle importance rankings. CTE replaces that random pick with a small, representative coreset built by kernel thinning, which is a principled way to keep points that best preserve the original data distribution. Result: less error from fewer samples.
How CTE Works
- Compress the dataset using kernel thinning (COMPRESS++), which minimizes a distribution gap (MMD) between the compressed sample and full data.
- Explain using your favorite method, but with the compressed set as background (and even foreground, when relevant). The theory shows: if your compressed set matches the original distribution better, the explanation error is provably bounded and smaller.
Highlights From the Paper
- Accuracy: On five benchmark datasets, CTE made explanations 20–45% more accurate and about 50% more consistent, compared to the baseline random sampling approach.
- Efficiency: You reach the same error with 2–3 × fewer samples → 2–3 × fewer model inferences.
- Broad applicability: Works with SHAP, SAGE, Expected Gradients, and Feature Effects; across tabular and vision setups.
Key Technical Insight
CTE’s success is in minimizing the maximum mean discrepancy (MMD) between the original and sampled distributions. The paper ties the explanation approximation error directly to this distance: smaller MMD means tighter error bounds for both local and global explanations.
Further Reading & Reference
Want steadier attributions without rewriting your stack? Published as a spotlight presentation at the A* conference ICLR 2025, you can explore the full paper and find the open-source code on GitHub.
Efficient and Accurate Explanation Estimation with Distribution Compression.
ICLR 2025 - 13th International Conference on Learning Representations. Singapore, Apr 24-28, 2025. Spotlight Presentation. URL GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

02.04.2026
How AI Avatars Shape Perceived Fairness
Accepted at CHI 2026, this study shows how the race and gender of AI interview avatars shape perceptions of fairness and bias in automated hiring.

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

