18.09.2025

GCE-Pose – Predicting Whole Objects From Partial Views
MCML Research Insight - With Weihang Li, Junwen Huang, Hyunjun Jung, Nassir Navab, and Benjamin Busam
Imagine trying to identify the full shape of a familiar object, e.g. a mug, when only its handle is visible. That’s the challenge a computer faces when estimating the pose of an object (its orientation and size) from partial data.
GCE‑Pose, a new approach from MCML Junior Members Weihang Li, Junwen Huang, Hyunjun Jung, Benjamin Busam, MCML PI Nassir Navab and collaborators Hongli XU and Peter KT Yu, introduced at CVPR 2025, tackles this with remarkable finesse.
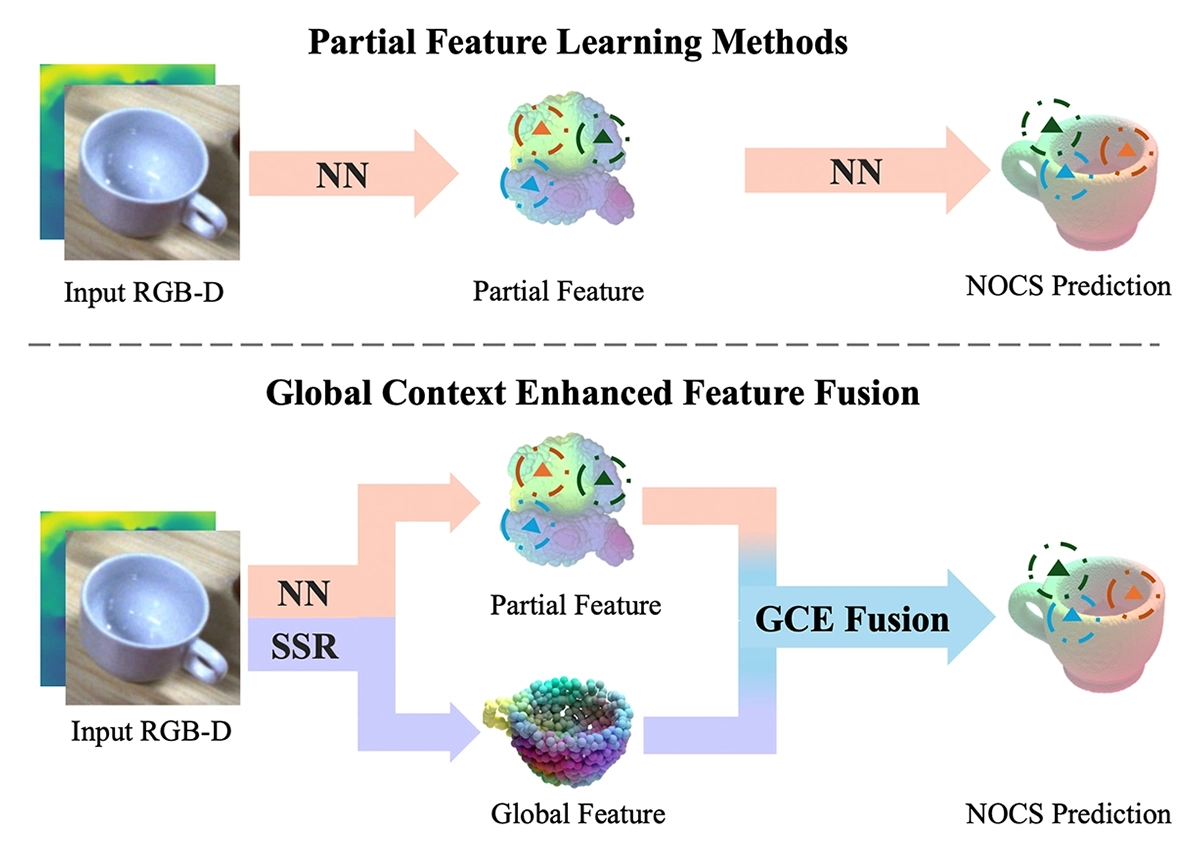
©Li et al.
Figure 1: Why GCE-Pose outperforms prior methods: Instead of relying solely on noisy partial features, it uses reconstructed global context to guide pose prediction, resulting in more accurate and robust estimates.
«The key advantage of our approach is that semantic reconstruction becomes straightforward once the semantic prototype is established.»
Weihang Li et al.
MCML Junior Members
The Gist of GCE-Pose
The key idea is simple yet powerful: instead of guessing the pose based solely on what’s visible, GCE‑Pose reconstructs the whole object, even when only a fragment is visible, and uses that global insight to make a smarter prediction.
How It Works: Three Clever Steps
(1) Robust Partial Feature Extraction
- Before filling in the gaps, GCE-Pose first finds the most reliable details in the visible part of the object. It identifies distinctive “landmarks” (keypoints) that stay consistent even when much of the object is hidden. These serve as the solid foundation for reconstruction.
(2) Semantic Shape Reconstruction (SSR)
- Once it has those keypoints, GCE-Pose uses its Deep Linear Semantic Shape Model to reconstruct a complete 3D version of the object. It starts with a category prototype (like a generic mug) and morphs it to match what’s visible.
- It also enriches the shape with semantic cues - details about different parts of the object learned from many examples - so it’s not just a guess at the geometry but also the meaning of each part.
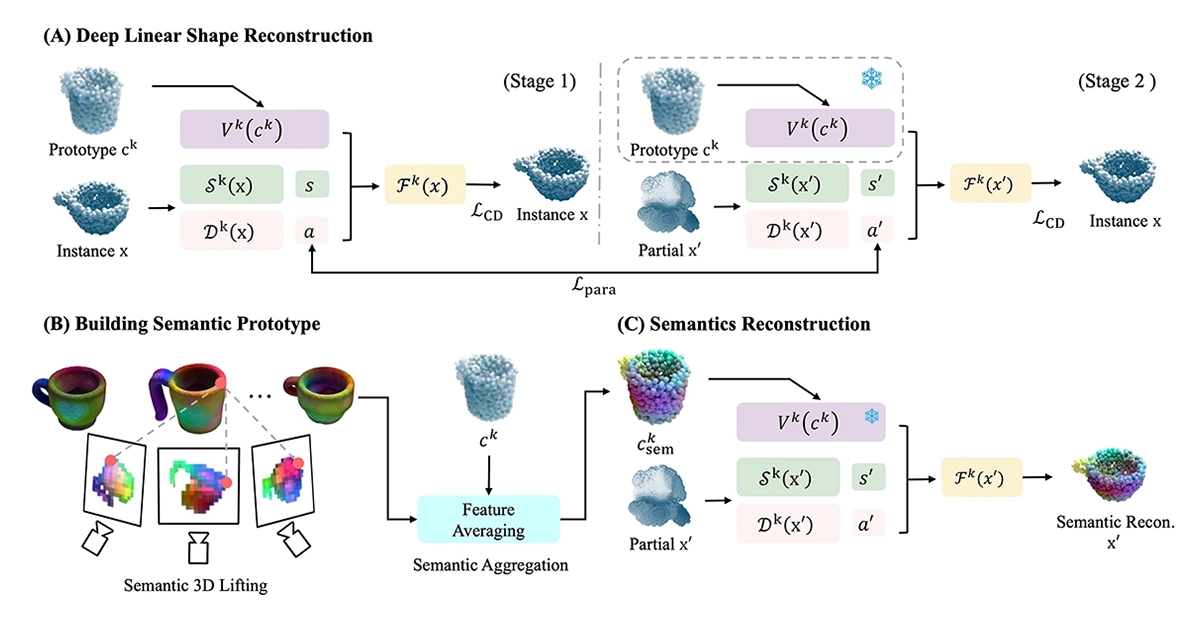
©Li et al.
Figure 2: How Semantic Shape Reconstruction works: A deep linear model deforms a category prototype to match the visible part of an object, builds a semantic prototype from multi-view features, and reconstructs the complete 3D shape with rich semantic cues.
(3) Global Context Enhanced (GCE) Fusion
- With the full semantic shape reconstructed, GCE-Pose fuses it with the partial view’s keypoint features. This is done using an attention mechanism, where the global reconstruction provides extra context for each visible point.
- This fusion bridges the gap between the noisy, incomplete real-world observation and the clean, complete mental model and results in a more robust pose estimation.
The GCE-Pose Pipeline at a Glance
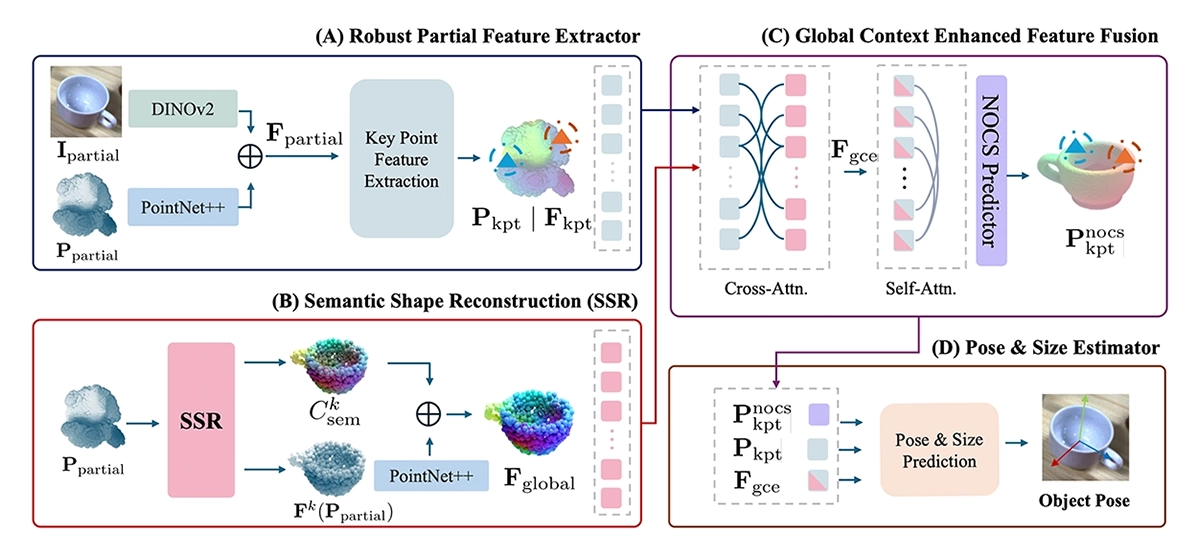
©Li et al.
Figure 3: The GCE-Pose pipeline: (A) extracts key local features from partial RGB-D views, (B) reconstructs a full semantic 3D shape, (C) fuses global context with local features via attention, and (D) predicts the final object pose and size.
«GCE-Pose significantly outperforms existing methods on challenging real-world datasets… demonstrating robustness to occlusions and strong generalization to novel instances.»
Weihang Li et al.
MCML Junior Members
Results
When tested on challenging real-world datasets like HouseCat6D and NOCS‑REAL275, GCE‑Pose consistently outperforms prior methods. Sometimes reducing pose error by up to 16% on tight benchmarks. That’s the difference between a blurry guess and a precise estimate, even in cluttered or occluded scenes.
Why It Matters
For robotics, augmented reality, and self-driving systems, knowing an object’s pose is crucial. GCE‑Pose’s ability to “see the whole from the part” is a leap toward systems that understand our 3D world even under imperfect conditions.
Check out the full paper presented at the prestigious A* conference CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition, one of the highest-ranked AI/ML conferences.
GCE-Pose: Global Context Enhancement for Category-level Object Pose Estimation.
CVPR 2025 - IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA, Jun 11-15, 2025. DOI GitHub
You can explore supplementary material and more on the GCE-Pose Project Page.
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related



09.04.2026
Nikita Araslanov Receives Prestigious Emmy Noether Grant
Nikita Araslanov, MCML Junior Member, awarded Emmy Noether Grant to establish an independent AI research group at TUM.

