31.07.2025

From Vulnerable to Verified: Exact Certificates Shield Models From Label‑Flipping
MCML Research Insight - With Lukas Gosch, Stephan Günnemann and Debarghya Ghoshdastidar
Machine‑learning models can be undermined before training even starts. By silently altering a small share of training labels - marking “spam” as “not‑spam,” for instance - an attacker can cut accuracy by double‑digit percentages.
The paper “Exact Certification of (Graph) Neural Networks Against Label Poisoning” by MCML Junior Member Lukas Gosch, PIs Stephan Günnemann and Debarghya Ghoshdastidar and collaborator Mahalakshmi Sabanayagam, introduces the first exact guarantees that a neural network will remain stable under a prescribed number of label flips. Although demonstrated on graph‑neural networks (GNNs), the method applies to any sufficiently wide neural network.
How the Certification Works
©Gosch et al.
Figure 1: Illustration of the label-flipping certificate
- Neural‑tangent view. In the wide‑network limit, training behaves like a support‑vector machine using the network’s neural tangent kernel (NTK).
- Single‑level reformulation. Substituting this NTK model allows to convert the attacker‑versus‑learner game for certification into one optimization problem.
- Mixed‑integer linear program. That problem is expressed as a mixed‑integer linear program whose solution yields (i) sample‑wise certificates for individual test nodes and (ii) collective certificates for the entire test set.
What Experiments Show
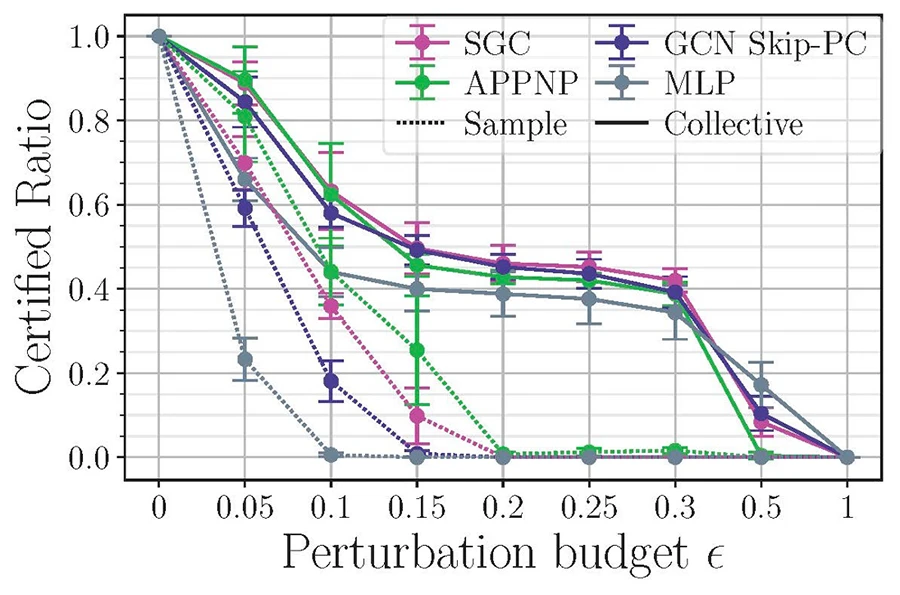
©Gosch et al.
Figure 2: Certified ratios (the share of test‑set predictions that the certificate proves cannot be overturned even if an attacker flips up to a fraction of the training labels) of selected architectures as calculated with the sample-wise and collective certificate on the Cora-MLb dataset.
- No universal best architecture. The most robust GNN depends on the data set.
- Design choices matter. Linear activations improve robustness, while deeper architectures often weaken it.
- A robustness plateau. Collective certificates reveal a flattening of vulnerability at medium attack budgets - an effect not noted before (see Figure 2).
«Machine learning models are highly vulnerable to label flipping, i.e., the adversarial modification (poisoning) of training labels to compromise performance.»
Lukas Gosch et al.
MCML Junior Members
Practical Implications
Because the approach relies only on the NTK, it extends to standard (non‑graph) wide neural networks, giving practitioners the first provable defence against label poisoning in deep learning.
«There is no silver bullet: robustness hierarchies of GNNs are strongly data dependent.»
Lukas Gosch et al.
MCML Junior Members
Key Takeaway
Exact certification shifts robustness from a best‑effort practice to a provable property. For anyone concerned about poisoned training data, this work provides a clear path toward verifiably trustworthy machine‑learning models.
Interested in Exploring Further?
Published as a spotlight presentation at at the A* conference ICLR 2025, you can explore the full paper—including proofs, algorithmic details, and additional experiments—and find the open-source code on GitHub.
Exact Certification of (Graph) Neural Networks Against Label Poisoning.
ICLR 2025 - 13th International Conference on Learning Representations. Singapore, Apr 24-28, 2025. Spotlight Presentation. URL GitHub
Share Your Research!
Get in touch with us!
Are you an MCML Junior Member and interested in showcasing your research on our blog?
We’re happy to feature your work—get in touch with us to present your paper.
Related

02.04.2026
How AI Avatars Shape Perceived Fairness
Accepted at CHI 2026, this study shows how the race and gender of AI interview avatars shape perceptions of fairness and bias in automated hiring.

24.03.2026
Cybersecurity: “Even Smart Light Bulbs Harbor Risks”
Interview with computer science expert Johannes Kinder on digital security in everyday life.

24.03.2026
MCML Members Win Most Cited Article Award at ECR 2026
MCML researchers win top citation award for ChatGPT radiology study, highlighting benefits and risks in patient communication.

